Pydantic Downloads from PyPI vs. Django
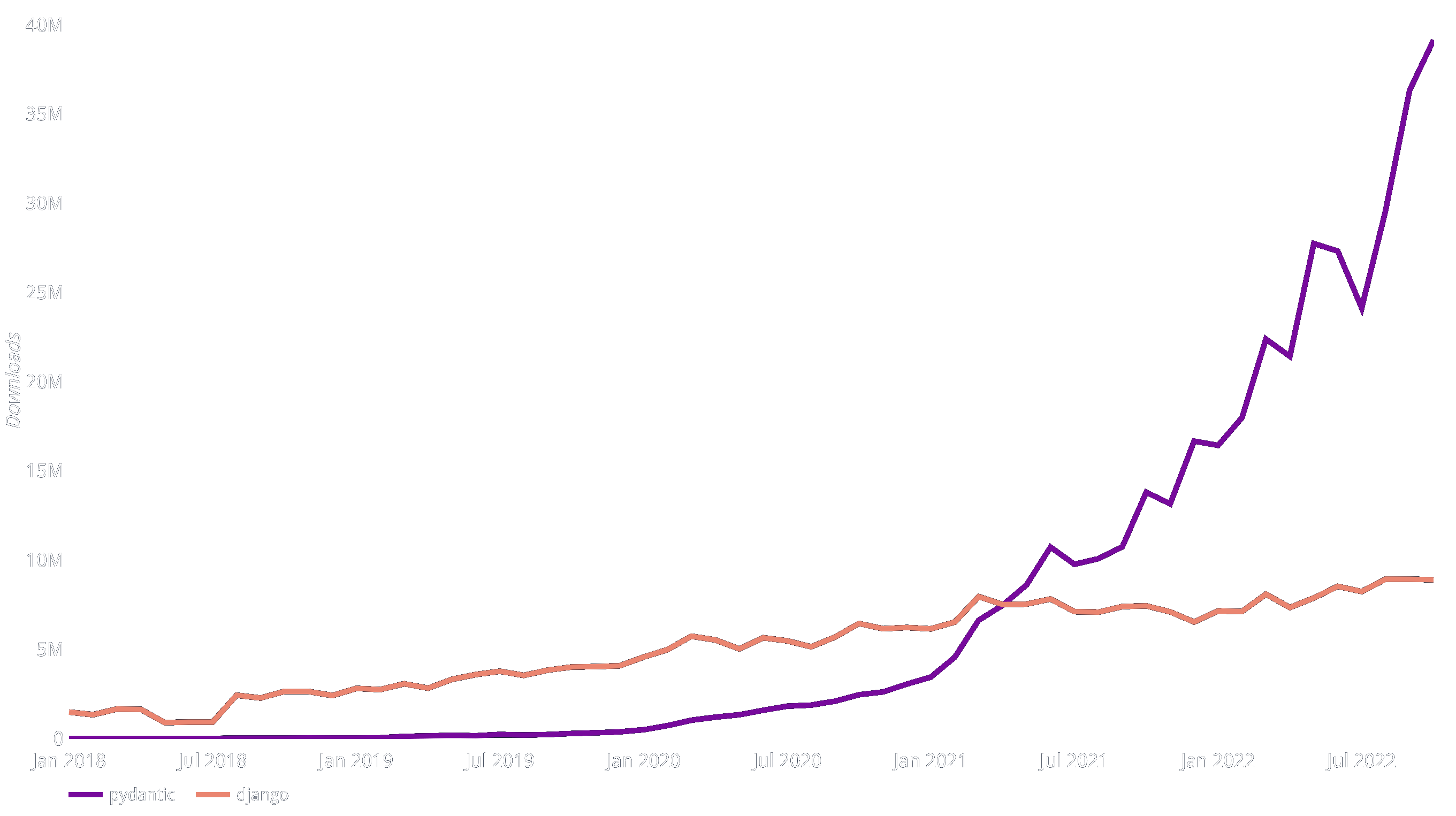
By my rough estimate, Pydantic is used by 12% of professional web developers! [†](#3-quot12-of-professional-web-developersquot-claim)
But Pydantic wasn't the first (or last) such library. Why has it been so successful?
I believe it comes down to two things:
1. We've always made developer experience the first priority.
2. We've leveraged technologies which developers already understand — most notably, Python type annotations.
In short, we've made Pydantic easy to get started with, and easy to do powerful things with.
I believe the time is right to apply those principles to other, bigger challenges.
"The Cloud" is still relatively new (think about what cars or tractors looked like 15 years after their conception), and
while it has already transformed our lives, it has massive shortcomings. I think we're uniquely positioned to address
some of these shortcomings.
We'll start by transforming the way those 12% of web developers who already know and trust Pydantic use cloud services
to build and deploy web applications. Then, we'll move on to help the other 88%!
### Cloud services suck (at least for us developers)
Picture the driving position of a 1950s tractor — steel seat, no cab, knobs sticking out of the engine compartment near
the component they control, hot surfaces just waiting for you to lean on them. Conceptually, this isn't surprising — the
tractor was a tool to speed up farming; its driver was an afterthought, and as long as they could manage to operate it
there was no value in making the experience pleasant or comfortable.

Today's cloud services have the look and feel of that tractor. They're conceived by infrastructure people who care about
efficient computation, fast networking, and cheap storage. The comfort and convenience of the developers who need to
drive these services to build end-user facing applications has been an afterthought.
Both the tractor and the cloud service of the past made sense: The majority of people who made the purchasing decisions
didn't operate them, and those who did had little influence. Why bother making them nice to operate?
> _"At least it's not a ~~cart horse~~ Windows box in the corner — quit complaining!"_
Just as the experience of driving tractors transformed as their drivers' pay and influence increased, so cloud services
are going through a transformation as their operators' pay and influence increases significantly.
There are many examples now of services and tools that are winning against incumbents because of great developer
experience:
- [Stripe](https://stripe.com) is winning in payments despite massive ecosystem of incumbents
- [Sentry](https://sentry.io/welcome/) is winning in application monitoring, even though you can send, store, and view the same data in CloudWatch et al. more cheaply
- [Vercel](https://vercel.com/) is winning in application hosting by focusing on one framework — Next.js
- [Python](https://www.tiobe.com/tiobe-index/) is winning against other programming languages, even though it's not backed by a massive corporation
- [Pydantic](https://docs.pydantic.dev/) is winning in data validation for Python, even though it's far from the first such library
In each case the developer experience is markedly better than what came before, and developers have driven adoption.
There is a massive opportunity to create cloud services with great developer experience at their heart.
I think we're well positioned to be part of it.
### Developers are still drowning under the weight of duplication
The story of the cloud has been about reducing duplication, abstracting away infrastructure and boilerplate:
co-location facilities with servers, cages and wires gave way to VMs. VMs gave way to PaaS offerings where you
just provide your application code. Serverless is challenging PaaS by offering to remove scaling worries.
At each step, cloud providers took work off engineers which was common to many customers.
But this hasn't gone far enough. Think about the last web application you worked on —
how many of the views or components were unique to your app?
Sure, you fitted them together in a unique way, but many (20%, 50%, maybe even 80%?) will exist hundreds or thousands of
times in other code bases. Couldn't many of those components, views, and utilities be shared with other apps without
affecting the value of your application? Again, reducing duplication, and reducing the time and cost of building an
application.
At the same time, serverless, despite being the trendiest way to deploy applications for the last few years, has made
much of this worse — complete web frameworks have often been switched out for bare-bones entry points which lack
even the most basic functionality of a web framework like routing, error handling, or database integration.
What if we could build a platform with the best of all worlds? Taking the final step in reducing the boilerplate
and busy-work of building web applications — allowing developers to write nothing more than the core logic which
makes their application unique and valuable?
And all with a developer experience to die for.
## What, specifically, are we building?
I'm not sharing details yet :).
The immediate plan is to hire the brightest developers I can find and work with them to refine our vision and exactly
what we're building while we finish and release Pydantic V2.
While I have some blueprints in my head of the libraries and services we want to build, we have a lot of options
for exactly where to go; we won't constrain what we can design by making any commitments now.
**If you're interested in what we're doing, hit subscribe on
[this GitHub issue](https://github.com/pydantic/pydantic/issues/5063).
We'll comment there when we have
more concrete information.**
## The plan
The plan, in short, is this:
1. Hire the best developers from around the world (see "We're Hiring" below)
2. Finish and release Pydantic V2, and continue to maintain, support and develop Pydantic over the years
3. Build cloud services and developer tools that developers love
Pydantic, the open source project, will be a cornerstone of the company. It'll be a key technical component
in what we're building and an important asset to help convince developers that the commercial tools and services
we build will be worth adopting. It will remain open source and MIT licenced, and support and development will
accelerate.
I'm currently working full time on Pydantic V2 (learn more from the [previous blog post](https://docs.pydantic.dev/blog/pydantic-v2/)).
It should be released later this year, hopefully in Q1. V2 is a massive advance for Pydantic — the core has been
re-written in Rust, making Pydantic V2 around 17x faster than V1. But there are lots of other goodies: strict mode,
composable validators, validation context, and more. I can't wait to get Pydantic V2 released and see how the community
uses it.
We'll keep working closely with [other open source libraries](https://github.com/topics/pydantic) that use and depend
on Pydantic as we have up to this point, making sure the whole Pydantic ecosystem continues to thrive.
_On a side note: Now that I'm paid to work on Pydantic, I'll be sharing all future open source sponsorship among
other open source projects we rely on._
## We ~~are~~ were hiring
We've had an extraordinary response to this announcement, and have hired an extremely talented team of developers.
We therefore aren't actively hiring at this time. Please follow us on Twitter/LinkedIn/Mastodon to hear about future
opportunities.
~~If you're a senior Python or full stack developer and think the ideas above are exciting, we'd love to hear from you.
Please email [careers@pydantic.dev](mailto:careers@pydantic.dev) with a brief summary of your skills and experience,
including links to your GitHub profile and your CV.~~
## Appendix
### "12% of professional web developers" claim
At first glance this seems like a fairly incredible number, where does it come from?
According to the
[StackOverflow developer survey 2022](https://survey.stackoverflow.co/2022/#section-most-popular-technologies-web-frameworks-and-technologies),
FastAPI is used by 6.01% of professional developers.
According to my survey of Pydantic users, Pydantic's usage is split roughly into:
- 25% FastAPI
- 25% other web development
- 50% everything else
That matches the numbers from PyPI downloads, which shows that (as of 2023-01-31)
[Pydantic has 46m](https://pepy.tech/project/pydantic) downloads in the last 30 days, while
[FastAPI has 10.7m](https://pepy.tech/project/fastapi) — roughly 25%.
Based on these numbers, I estimate Pydantic is used for web development by about twice the number who use it through
FastAPI — roughly 12%.
1b:Tcbb9,
Updated late 10 Jul 2022, see [pydantic#4226](https://github.com/pydantic/pydantic/pull/4226).
---
I've spoken to quite a few people about pydantic V2, and mention it in passing even more.
I owe people a proper explanation of the plan for V2:
- What we will add
- What we will remove
- What we will change
- How I'm intending to go about completing it and getting it released
- Some idea of timeframe :fearful:
Here goes...
---
Enormous thanks to
[Eric Jolibois](https://github.com/PrettyWood), [Laurence Watson](https://github.com/Rabscuttler),
[Sebastián Ramírez](https://github.com/tiangolo), [Adrian Garcia Badaracco](https://github.com/adriangb),
[Tom Hamilton Stubber](https://github.com/tomhamiltonstubber), [Zac Hatfield-Dodds](https://github.com/Zac-HD),
[Tom](https://github.com/czotomo) & [Hasan Ramezani](https://github.com/hramezani)
for reviewing this blog post, putting up with (and correcting) my horrible typos and making great suggestions
that have made this post and Pydantic V2 materially better.
---
## Plan & Timeframe
I'm currently taking a kind of sabbatical after leaving my last job to get pydantic V2 released.
Why? I ask myself that question quite often.
I'm very proud of how much pydantic is used, but I'm less proud of its internals.
Since it's something people seem to care about and use quite a lot
(26m downloads a month, used by 72k public repos, 10k stars).
I want it to be as good as possible.
While I'm on the subject of why, how and my odd sabbatical: if you work for a large company who use pydantic a lot,
you might encourage the company to **sponsor me a meaningful amount**,
like [Salesforce did](https://twitter.com/samuel_colvin/status/1501288247670063104)
(if your organisation is not open to donations, I can also offer consulting services).
This is not charity, recruitment or marketing - the argument should be about how much the company will save if
pydantic is 10x faster, more stable and more powerful - it would be worth paying me 10% of that to make it happen.
Before pydantic V2 can be released, we need to release pydantic V1.10 - there are lots of changes in the main
branch of pydantic contributed by the community, it's only fair to provide a release including those changes,
many of them will remain unchanged for V2, the rest will act as a requirement to make sure pydantic V2 includes
the capabilities they implemented.
The basic road map for me is as follows:
1. Implement a few more features in pydantic-core, and release a first version, see [below](#motivation--pydantic-core)
2. Work on getting pydantic V1.10 out - basically merge all open PRs that are finished
3. Release pydantic V1.10
4. Delete all stale PRs which didn't make it into V1.10, apologise profusely to their authors who put their valuable
time into pydantic only to have their PRs closed :pray:
(and explain when and how they can rebase and recreate the PR)
5. Rename `master` to `main`, seems like a good time to do this
6. Change the main branch of pydantic to target V2
7. Start tearing pydantic code apart and see how many existing tests can be made to pass
8. Rinse, repeat
9. Release pydantic V2 :tada:
Plan is to have all this done by the end of October, definitely by the end of the year.
### Breaking Changes & Compatibility :pray:
While we'll do our best to avoid breaking changes, some things will break.
As per the [greatest pun in modern TV history](https://youtu.be/ezAlySFluEk).
> You can't make a Tomelette without breaking some Greggs.
Where possible, if breaking changes are unavoidable, we'll try to provide warnings or errors to make sure those
changes are obvious to developers.
## Motivation & `pydantic-core`
Since pydantic's initial release, with the help of wonderful contributors
[Eric Jolibois](https://github.com/PrettyWood),
[Sebastián Ramírez](https://github.com/tiangolo),
[David Montague](https://github.com/dmontagu) and many others, the package and its usage have grown enormously.
The core logic however has remained mostly unchanged since the initial experiment.
It's old, it smells, it needs to be rebuilt.
The release of version 2 is an opportunity to rebuild pydantic and correct many things that don't make sense -
**to make pydantic amazing :rocket:**.
The core validation logic of pydantic V2 will be performed by a separate package
[pydantic-core](https://github.com/pydantic/pydantic-core) which I've been building over the last few months.
_pydantic-core_ is written in Rust using the excellent [pyo3](https://pyo3.rs) library which provides rust bindings
for python.
The motivation for building pydantic-core in Rust is as follows:
1. **Performance**, see [below](#performance--section)
2. **Recursion and code separation** - with no stack and little-to-no overhead for extra function calls,
Rust allows pydantic-core to be implemented as a tree of small validators which call each other,
making code easier to understand and extend without harming performance
3. **Safety and complexity** - pydantic-core is a fairly complex piece of code which has to draw distinctions
between many different errors, Rust is great in situations like this,
it should minimise bugs (:fingers_crossed:) and allow the codebase to be extended for a long time to come
:::note
The python interface to pydantic shouldn't change as a result of using pydantic-core, instead
pydantic will use type annotations to build a schema for pydantic-core to use.
:::
pydantic-core is usable now, albeit with an unintuitive API, if you're interested, please give it a try.
pydantic-core provides validators for common data types,
[see a list here](https://github.com/pydantic/pydantic-core/blob/main/pydantic_core/schema_types.py#L314).
Other, less commonly used data types will be supported via validator functions implemented in pydantic, in Python.
See [pydantic-core#153](https://github.com/pydantic/pydantic-core/issues/153)
for a summary of what needs to be completed before its first release.
## Headlines
Here are some of the biggest changes expected in V2.
### Performance :+1:
As a result of the move to Rust for the validation logic
(and significant improvements in how validation objects are structured) pydantic V2 will be significantly faster
than pydantic V1.
Looking at the pydantic-core [benchmarks](https://github.com/pydantic/pydantic-core/tree/main/tests/benchmarks)
today, pydantic V2 is between 4x and 50x faster than pydantic V1.9.1.
In general, pydantic V2 is about 17x faster than V1 when validating a model containing a range of common fields.
### Strict Mode :+1:
People have long complained about pydantic for coercing data instead of throwing an error.
E.g. input to an `int` field could be `123` or the string `"123"` which would be converted to `123`
While this is very useful in many scenarios (think: URL parameters, environment variables, user input),
there are some situations where it's not desirable.
pydantic-core comes with "strict mode" built in. With this, only the exact data type is allowed, e.g. passing
`"123"` to an `int` field would result in a validation error.
This will allow pydantic V2 to offer a `strict` switch which can be set on either a model or a field.
### Formalised Conversion Table :+1:
As well as complaints about coercion, another legitimate complaint was inconsistency around data conversion.
In pydantic V2, the following principle will govern when data should be converted in "lax mode" (`strict=False`):
> If the input data has a SINGLE and INTUITIVE representation, in the field's type, AND no data is lost
> during the conversion, then the data will be converted; otherwise a validation error is raised.
> There is one exception to this rule: string fields -
> virtually all data has an intuitive representation as a string (e.g. `repr()` and `str()`), therefore
> a custom rule is required: only `str`, `bytes` and `bytearray` are valid as inputs to string fields.
Some examples of what that means in practice:
| Field Type | Input | Single & Intuitive R. | All Data Preserved | Result |
| ---------- | ----------------------- | --------------------- | ------------------ | ------- |
| `int` | `"123"` | ![check][check] | ![check][check] | Convert |
| `int` | `123.0` | ![check][check] | ![check][check] | Convert |
| `int` | `123.1` | ![check][check] | ![x][x] | Error |
| `date` | `"2020-01-01"` | ![check][check] | ![check][check] | Convert |
| `date` | `"2020-01-01T00:00:00"` | ![check][check] | ![check][check] | Convert |
| `date` | `"2020-01-01T12:00:00"` | ![check][check] | ![x][x] | Error |
| `int` | `b"1"` | ![x][x] | ![check][check] | Error |
(For the last case converting `bytes` to an `int` could reasonably mean `int(bytes_data.decode())` or
`int.from_bytes(b'1', 'big/little')`, hence an error)
In addition to the general rule, we'll provide a conversion table which defines exactly what data will be allowed
to which field types. See [the table below](#formalised-conversion-table--section) for a start on this.
### Built in JSON support :+1:
pydantic-core can parse JSON directly into a model or output type, this both improves performance and avoids
issue with strictness - e.g. if you have a strict model with a `datetime` field, the input must be a
`datetime` object, but clearly that makes no sense when parsing JSON which has no `datatime` type.
Same with `bytes` and many other types.
Pydantic V2 will therefore allow some conversion when validating JSON directly, even in strict mode
(e.g. `ISO8601 string -> datetime`, `str -> bytes`) even though this would not be allowed when validating
a python object.
In future direct validation of JSON will also allow:
- parsing in a separate thread while starting validation in the main thread
- line numbers from JSON to be included in the validation errors
(These features will not be included in V2, but instead will hopefully be added later.)
:::note
Pydantic has always had special support for JSON, that is not going to change.
:::
While in theory other formats could be specifically supported, the overheads and development time are significant and I don't think there's another format that's used widely enough to be worth specific logic. Other formats can be parsed to python then validated,similarly when serializing, data can be exported to a python object, then serialized, see [below](#improvements-to-dumpingserializationexport---section).
### Validation without a Model :+1:
In pydantic V1 the core of all validation was a pydantic model, this led to a significant performance penalty
and extra complexity when the output data type was not a model.
pydantic-core operates on a tree of validators with no "model" type required at the base of that tree.
It can therefore validate a single `string` or `datetime` value, a `TypedDict` or a `Model` equally easily.
This feature will provide significant addition performance improvements in scenarios like:
- Adding validation to `dataclasses`
- Validating URL arguments, query strings, headers, etc. in FastAPI
- Adding validation to `TypedDict`
- Function argument validation
- Adding validation to your custom classes, decorators...
In effect - anywhere where you don't care about a traditional model class instance.
We'll need to add standalone methods for generating JSON Schema and dumping these objects to JSON, etc.
### Required vs. Nullable Cleanup :+1:
Pydantic previously had a somewhat confused idea about "required" vs. "nullable". This mostly resulted from
my misgivings about marking a field as `Optional[int]` but requiring a value to be provided but allowing it to be
`None` - I didn't like using the word "optional" in relation to a field which was not optional.
In pydantic V2, pydantic will move to match dataclasses, thus:
```py title="Required vs. Nullable" test="skip" lint="skip" upgrade="skip"
from pydantic import BaseModel
class Foo(BaseModel):
f1: str # required, cannot be None
f2: str | None # required, can be None - same as Optional[str] / Union[str, None]
f3: str | None = None # not required, can be None
f4: str = 'Foobar' # not required, but cannot be None
```
### Validator Function Improvements :+1: :+1: :+1:
This is one of the changes in pydantic V2 that I'm most excited about, I've been talking about something
like this for a long time, see [pydantic#1984](https://github.com/pydantic/pydantic/issues/1984), but couldn't
find a way to do this until now.
Fields which use a function for validation can be any of the following types:
- **function before mode** - where the function is called before the inner validator is called
- **function after mode** - where the function is called after the inner validator is called
- **plain mode** - where there's no inner validator
- **wrap mode** - where the function takes a reference to a function which calls the inner validator,
and can therefore modify the input before inner validation, modify the output after inner validation, conditionally
not call the inner validator or catch errors from the inner validator and return a default value, or change the error
An example how a wrap validator might look:
```py title="Wrap mode validator function" test="skip" lint="skip" upgrade="skip"
from datetime import datetime
from pydantic import BaseModel, ValidationError, validator
class MyModel(BaseModel):
timestamp: datetime
@validator('timestamp', mode='wrap')
def validate_timestamp(cls, v, handler):
if v == 'now':
# we don't want to bother with further validation,
# just return the new value
return datetime.now()
try:
return handler(v)
except ValidationError:
# validation failed, in this case we want to
# return a default value
return datetime(2000, 1, 1)
```
As well as being powerful, this provides a great "escape hatch" when pydantic validation doesn't do what you need.
### More powerful alias(es) :+1:
pydantic-core can support alias "paths" as well as simple string aliases to flatten data as it's validated.
Best demonstrated with an example:
```py title="Alias paths" test="skip" lint="skip" upgrade="skip"
from pydantic import BaseModel, Field
class Foo(BaseModel):
bar: str = Field(aliases=[['baz', 2, 'qux']])
data = {
'baz': [
{'qux': 'a'},
{'qux': 'b'},
{'qux': 'c'},
{'qux': 'd'},
]
}
foo = Foo(**data)
assert foo.bar == 'c'
```
`aliases` is a list of lists because multiple paths can be provided, if so they're tried in turn until a value is found.
Tagged unions will use the same logic as `aliases` meaning nested attributes can be used to select a schema
to validate against.
### Improvements to Dumping/Serialization/Export :+1: :confused:
(I haven't worked on this yet, so these ideas are only provisional)
There has long been a debate about how to handle converting data when extracting it from a model.
One of the features people have long requested is the ability to convert data to JSON compliant types while
converting a model to a dict.
My plan is to move data export into pydantic-core, with that, one implementation can support all export modes without
compromising (and hopefully significantly improving) performance.
I see four different export/serialization scenarios:
1. Extracting the field values of a model with no conversion, effectively `model.__dict__` but with the current filtering
logic provided by `.dict()`
2. Extracting the field values of a model recursively (effectively what `.dict()` does now) - sub-models are converted to
dicts, but other fields remain unchanged.
3. Extracting data and converting at the same time (e.g. to JSON compliant types)
4. Serializing data straight to JSON
I think all 4 modes can be supported in a single implementation, with a kind of "3.5" mode where a python function
is used to convert the data as the user wishes.
The current `include` and `exclude` logic is extremely complicated, but hopefully it won't be too hard to
translate it to Rust.
We should also add support for `validate_alias` and `dump_alias` as well as the standard `alias`
to allow for customising field keys.
### Validation Context :+1:
Pydantic V2 will add a new optional `context` argument to `model_validate` and `model_validate_json`
which will allow you to pass information not available when creating a model to validators.
See [pydantic#1549](https://github.com/pydantic/pydantic/issues/1549) for motivation.
Here's an example of `context` might be used:
```py title="Context during Validation" test="skip" lint="skip" upgrade="skip"
from pydantic import BaseModel, EmailStr, validator
class User(BaseModel):
email: EmailStr
home_country: str
@validator('home_country')
def check_home_country(cls, v, context):
if v not in context['countries']:
raise ValueError('invalid country choice')
return v
async def add_user(post_data: bytes):
countries = set(await db_connection.fetch_all('select code from country'))
user = User.model_validate_json(post_data, context={'countries': countries})
...
```
:::note
We (actually mostly Sebastián :wink:) will have to make some changes to FastAPI to fully leverage `context`
as we'd need some kind of dependency injection to build context before validation so models can still be passed as arguments to views. I'm sure he'll be game.
:::
:::deter
Although this will make it slightly easier to run synchronous IO (HTTP requests, DB. queries, etc.)
from within validators, I strongly advise you keep IO separate from validation - do it before and use context,
do it afterwards, avoid where possible making queries inside validation.
:::
### Model Namespace Cleanup :+1:
For years I've wanted to clean up the model namespace,
see [pydantic#1001](https://github.com/pydantic/pydantic/issues/1001). This would avoid confusing gotchas when field
names clash with methods on a model, it would also make it safer to add more methods to a model without risking
new clashes.
After much deliberation (and even giving a lightning talk at the python language submit about alternatives, see
[this discussion](https://discuss.python.org/t/better-fields-access-and-allowing-a-new-character-at-the-start-of-identifiers/14529)).
I've decided to go with the simplest and clearest approach, at the expense of a bit more typing:
All methods on models will start with `model_`, fields' names will not be allowed to start with `"model"`
(aliases can be used if required).
This will mean `BaseModel` will have roughly the following signature.
```py title="Context during Validation" test="skip" lint="skip" upgrade="skip"
class BaseModel:
model_fields: List[FieldInfo]
"""previously `__fields__`, although the format will change a lot"""
@classmethod
def model_validate(cls, data: Any, *, context=None) -> Self: # (1)
"""
previously `parse_obj()`, validate data
"""
@classmethod
def model_validate_json(
cls,
data: str | bytes | bytearray,
*,
context=None
) -> Self:
"""
previously `parse_raw(..., content_type='application/json')`
validate data from JSON
"""
@classmethod
def model_is_instance(cls, data: Any, *, context=None) -> bool: # (2)
"""
new, check if data is value for the model
"""
@classmethod
def model_is_instance_json(
cls,
data: str | bytes | bytearray,
*,
context=None
) -> bool:
"""
Same as `model_is_instance`, but from JSON
"""
def model_dump(
self,
include: ... = None,
exclude: ... = None,
by_alias: bool = False,
exclude_unset: bool = False,
exclude_defaults: bool = False,
exclude_none: bool = False,
mode: Literal['unchanged', 'dicts', 'json-compliant'] = 'unchanged',
converter: Callable[[Any], Any] | None = None
) -> Any:
"""
previously `dict()`, as before
with new `mode` argument
"""
def model_dump_json(self, ...) -> str:
"""
previously `json()`, arguments as above
effectively equivalent to `json.dump(self.model_dump(..., mode='json'))`,
but more performant
"""
def model_json_schema(self, ...) -> dict[str, Any]:
"""
previously `schema()`, arguments roughly as before
JSON schema as a dict
"""
def model_update_forward_refs(self) -> None:
"""
previously `update_forward_refs()`, update forward references
"""
@classmethod
def model_construct(
self,
_fields_set: set[str] | None = None,
**values: Any
) -> Self:
"""
previously `construct()`, arguments roughly as before
construct a model with no validation
"""
@classmethod
def model_customize_schema(cls, schema: dict[str, Any]) -> dict[str, Any]:
"""
new, way to customize validation,
e.g. if you wanted to alter how the model validates certain types,
or add validation for a specific type without custom types or
decorated validators
"""
class ModelConfig:
"""
previously `Config`, configuration class for models
"""
```
1. see [Validation Context](#validation-context--section) for more information on `context`
2. see [`is_instance` checks](#is_instance-like-checks--section)
The following methods will be removed:
- `.parse_file()` - was a mistake, should never have been in pydantic
- `.parse_raw()` - partially replaced by `.model_validate_json()`, the other functionality was a mistake
- `.from_orm()` - the functionality has been moved to config, see [other improvements](#other-improvements--section) below
- `.schema_json()` - mostly since it causes confusion between pydantic validation schema and JSON schema,
and can be replaced with just `json.dumps(m.model_json_schema())`
- `.copy()` instead we'll implement `__copy__` and let people use the `copy` module
(this removes some functionality) from `copy()` but there are bugs and ambiguities with the functionality anyway
### Strict API & API documentation :+1:
When preparing for pydantic V2, we'll make a strict distinction between the public API and private functions & classes.
Private objects will be clearly identified as private via a `_internal` sub package to discourage use.
The public API will have API documentation. I've recently been working with the wonderful
[mkdocstrings](https://github.com/mkdocstrings/mkdocstrings) package for both
[dirty-equals](https://dirty-equals.helpmanual.io/) and
[watchfiles](https://watchfiles.helpmanual.io/) documentation. I intend to use `mkdocstrings` to generate complete
API documentation for V2.
This wouldn't replace the current example-based somewhat informal documentation style but instead will augment it.
### Error descriptions :+1:
The way line errors (the individual errors within a `ValidationError`) are built has become much more sophisticated
in pydantic-core.
There's a well-defined
[set of error codes and messages](https://github.com/pydantic/pydantic-core/blob/main/src/errors/kinds.rs).
More will be added when other types are validated via pure python validators in pydantic.
I would like to add a dedicated section to the documentation with extra information for each type of error.
This would be another key in a line error: `documentation`, which would link to the appropriate section in the
docs.
Thus, errors might look like:
```py title="Line Errors Example" test="skip" lint="skip" upgrade="skip"
[
{
'kind': 'greater_than_equal',
'loc': ['age'],
'message': 'Value must be greater than or equal to 18',
'input_value': 11,
'context': {'ge': 18},
'documentation': 'https://pydantic.dev/errors/#greater_than_equal',
},
{
'kind': 'bool_parsing',
'loc': ['is_developer'],
'message': 'Value must be a valid boolean, unable to interpret input',
'input_value': 'foobar',
'documentation': 'https://pydantic.dev/errors/#bool_parsing',
},
]
```
I own the `pydantic.dev` domain and will use it for at least these errors so that even if the docs URL
changes, the error will still link to the correct documentation. If developers don't want to show these errors to users,
they can always process the errors list and filter out items from each error they don't need or want.
### No pure python implementation :frowning:
Since pydantic-core is written in Rust, and I have absolutely no intention of rewriting it in python,
pydantic V2 will only work where a binary package can be installed.
pydantic-core will provide binaries in PyPI for (at least):
- **Linux**: `x86_64`, `aarch64`, `i686`, `armv7l`, `musl-x86_64` & `musl-aarch64`
- **MacOS**: `x86_64` & `arm64` (except python 3.7)
- **Windows**: `amd64` & `win32`
- **Web Assembly**: `wasm32`
(pydantic-core is [already](https://github.com/pydantic/pydantic-core/runs/7214195252?check_suite_focus=true)
compiled for wasm32 using emscripten and unit tests pass, except where cpython itself has
[problems](https://github.com/pyodide/pyodide/issues/2841))
Binaries for pypy are a work in progress and will be added if possible,
see [pydantic-core#154](https://github.com/pydantic/pydantic-core/issues/154).
Other binaries can be added provided they can be (cross-)compiled on github actions.
If no binary is available from PyPI, pydantic-core can be compiled from source if Rust stable is available.
The only place where I know this will cause problems is Raspberry Pi, which is a
[mess](https://github.com/piwheels/packages/issues/254) when it comes to packages written in Rust for Python.
Effectively, until that's fixed you'll likely have to install pydantic with
`pip install -i https://pypi.org/simple/ pydantic`.
### Pydantic becomes a pure python package :+1:
Pydantic V1.X is a pure python code base but is compiled with cython to provide some performance improvements.
Since the "hot" code is moved to pydantic-core, pydantic itself can go back to being a pure python package.
This should significantly reduce the size of the pydantic package and make unit tests of pydantic much faster.
In addition:
- some constraints on pydantic code can be removed once it no-longer has to be compilable with cython
- debugging will be easier as you'll be able to drop straight into the pydantic codebase as you can with other,
pure python packages
Some pieces of edge logic could get a little slower as they're no longer compiled.
### `is_instance` like checks :+1:
Strict mode also means it makes sense to provide an `is_instance` method on models which effectively run
validation then throws away the result while avoiding the (admittedly small) overhead of creating and raising
an error or returning the validation result.
To be clear, this isn't a real `isinstance` call, rather it is equivalent to
```py title="is_instance" test="skip" lint="skip" upgrade="skip"
class BaseModel:
...
@classmethod
def model_is_instance(cls, data: Any) -> bool:
try:
cls(**data)
except ValidationError:
return False
else:
return True
```
### I'm dropping the word "parse" and just using "validate" :neutral_face:
Partly due to the issues with the lack of strict mode,
I've gone back and forth between using the terms "parse" and "validate" for what pydantic does.
While pydantic is not simply a validation library (and I'm sure some would argue validation is not strictly what it does),
most people use the word **"validation"**.
It's time to stop fighting that, and use consistent names.
The word "parse" will no longer be used except when talking about JSON parsing, see
[model methods](#model-namespace-cleanup--section) above.
### Changes to custom field types :neutral_face:
Since the core structure of validators has changed from "a list of validators to call one after another" to
"a tree of validators which call each other", the
[`__get_validators__`](https://docs.pydantic.dev/usage/types/#classes-with-__get_validators__)
way of defining custom field types no longer makes sense.
Instead, we'll look for the attribute `__pydantic_validation_schema__` which must be a
pydantic-core compliant schema for validating data to this field type (the `function`
item can be a string, if so a function of that name will be taken from the class, see `'validate'` below).
Here's an example of how a custom field type could be defined:
```py title="New custom field types" test="skip" lint="skip" upgrade="skip"
from pydantic import ValidationSchema
class Foobar:
def __init__(self, value: str):
self.value = value
__pydantic_validation_schema__: ValidationSchema = {
'type': 'function',
'mode': 'after',
'function': 'validate',
'schema': {'type': 'str'},
}
@classmethod
def validate(cls, value):
if 'foobar' in value:
return Foobar(value)
else:
raise ValueError('expected foobar')
```
What's going on here: `__pydantic_validation_schema__` defines a schema which effectively says:
> Validate input data as a string, then call the `validate` function with that string, use the returned value
> as the final result of validation.
`ValidationSchema` is just an alias to
[`pydantic_core.Schema`](https://github.com/pydantic/pydantic-core/blob/main/pydantic_core/_types.py#L291)
which is a type defining the schema for validation schemas.
:::note
pydantic-core schema has full type definitions although since the type is recursive, mypy can't provide static type analysis, pyright however can.
We can probably provide one or more helper functions to make `__pydantic_validation_schema__` easier to generate.
:::
## Other Improvements :+1:
Some other things which will also change, IMHO for the better:
1. Recursive models with cyclic references - although recursive models were supported by pydantic V1,
data with cyclic references caused recursion errors, in pydantic-core cyclic references are correctly detected
and a validation error is raised
2. The reason I've been so keen to get pydantic-core to compile and run with wasm is that I want all examples
in the docs of pydantic V2 to be editable and runnable in the browser
3. Full support for `TypedDict`, including `total=False` - e.g. omitted keys,
providing validation schema to a `TypedDict` field/item will use `Annotated`, e.g. `Annotated[str, Field(strict=True)]`
4. `from_orm` has become `from_attributes` and is now defined at schema generation time
(either via model config or field config)
5. `input_value` has been added to each line error in a `ValidationError`, making errors easier to understand,
and more comprehensive details of errors to be provided to end users,
[pydantic#784](https://github.com/pydantic/pydantic/issues/784)
6. `on_error` logic in a schema which allows either a default value to be used in the event of an error,
or that value to be omitted (in the case of a `total=False` `TypedDict`),
[pydantic-core#151](https://github.com/pydantic/pydantic-core/issues/151)
7. `datetime`, `date`, `time` & `timedelta` validation is improved, see the
[speedate] Rust library I built specifically for this purpose for more details
8. Powerful "priority" system for optionally merging or overriding config in sub-models for nested schemas
9. Pydantic will support [annotated-types](https://github.com/annotated-types/annotated-types),
so you can do stuff like `Annotated[set[int], Len(0, 10)]` or `Name = Annotated[str, Len(1, 1024)]`
10. A single decorator for general usage - we should add a `validate` decorator which can be used:
- on functions (replacing `validate_arguments`)
- on dataclasses, `pydantic.dataclasses.dataclass` will become an alias of this
- on `TypedDict`s
- On any supported type, e.g. `Union[...]`, `Dict[str, Thing]`
- On Custom field types - e.g. anything with a `__pydantic_schema__` attribute
11. Easier validation error creation, I've often found myself wanting to raise `ValidationError`s outside
models, particularly in FastAPI
([here](https://github.com/samuelcolvin/foxglove/blob/a4aaacf372178f345e5ff1d569ee8fd9d10746a4/foxglove/exceptions.py#L137-L149)
is one method I've used), we should provide utilities to generate these errors
12. Improve the performance of `__eq__` on models
13. Computed fields, these having been an idea for a long time in pydantic - we should get them right
14. Model validation that avoids instances of subclasses leaking data (particularly important for FastAPI),
see [pydantic-core#155](https://github.com/pydantic/pydantic-core/issues/155)
15. We'll now follow [semvar](https://semver.org/) properly and avoid breaking changes between minor versions,
as a result, major versions will become more common
16. Improve generics to use `M(Basemodel, Generic[T])` instead of `M(GenericModel, Generic[T])` - e.g. `GenericModel`
can be removed; this results from no-longer needing to compile pydantic code with cython
## Removed Features & Limitations :frowning:
The emoji here is just for variation, I'm not frowning about any of this, these changes are either good IMHO
(will make pydantic cleaner, easier to learn and easier to maintain) or irrelevant to 99.9+% of users.
1. `__root__` custom root models are no longer necessary since validation on any supported data type is allowed
without a model
2. `.parse_file()` and `.parse_raw()`, partially replaced with `.model_validate_json()`,
see [model methods](#model-namespace-cleanup--section)
3. `.schema_json()` & `.copy()`, see [model methods](#model-namespace-cleanup--section)
4. `TypeError` are no longer considered as validation errors, but rather as internal errors, this is to better
catch errors in argument names in function validators.
5. Subclasses of builtin types like `str`, `bytes` and `int` are coerced to their parent builtin type,
this is a limitation of how pydantic-core converts these types to Rust types during validation, if you have a
specific need to keep the type, you can use wrap validators or custom type validation as described above
6. integers are represented in rust code as `i64`, meaning if you want to use ints where `abs(v) > 2^63 − 1`
(9,223,372,036,854,775,807), you'll need to use a [wrap validator](#validator-function-improvements----section) and your own logic
7. [Settings Management](https://docs.pydantic.dev/usage/settings/) ??? - I definitely don't want to
remove the functionality, but it's something of a historical curiosity that it lives within pydantic,
perhaps it should move to a separate package, perhaps installable alongside pydantic with
`pip install pydantic[settings]`?
8. The following `Config` properties will be removed or deprecated:
- `fields` - it's very old (it pre-dates `Field`), can be removed
- `allow_mutation` will be removed, instead `frozen` will be used
- `error_msg_templates`, it's not properly documented anyway, error messages can be customized with external logic if required
- `getter_dict` - pydantic-core has hardcoded `from_attributes` logic
- `json_loads` - again this is hard coded in pydantic-core
- `json_dumps` - possibly
- `json_encoders` - see the export "mode" discussion [above](#improvements-to-dumpingserializationexport---section)
- `underscore_attrs_are_private` we should just choose a sensible default
- `smart_union` - all unions are now "smart"
9. `dict(model)` functionality should be removed, there's a much clearer distinction now that in 2017 when I
implemented this between a model and a dict
## Features Remaining :neutral_face:
The following features will remain (mostly) unchanged:
- JSONSchema, internally this will need to change a lot, but hopefully the external interface will remain unchanged
- `dataclass` support, again internals might change, but not the external interface
- `validate_arguments`, might be renamed, but otherwise remain
- hypothesis plugin, might be able to improve this as part of the general cleanup
## Questions :question:
I hope the explanation above is useful. I'm sure people will have questions and feedback; I'm aware
I've skipped over some features with limited detail (this post is already fairly long :sleeping:).
To allow feedback without being overwhelmed, I've created a "Pydantic V2" category for
[discussions on github](https://github.com/pydantic/pydantic/discussions/categories/pydantic-v2) - please
feel free to create a discussion if you have any questions or suggestions.
We will endeavour to read and respond to everyone.
---
## Implementation Details :nerd:
(This is yet to be built, so these are nascent ideas which might change)
At the center of pydantic v2 will be a `PydanticValidator` class which looks roughly like this
(note: this is just pseudo-code, it's not even valid python and is only supposed to be used to demonstrate the idea):
```py title="PydanticValidator" test="skip" lint="skip" upgrade="skip"
# type identifying data which has been validated,
# as per pydantic-core, this can include "fields_set" data
ValidData = ...
# any type we can perform validation for
AnyOutputType = ...
class PydanticValidator:
def __init__(self, output_type: AnyOutputType, config: Config):
...
def validate(self, input_data: Any) -> ValidData:
...
def validate_json(self, input_data: str | bytes | bytearray) -> ValidData:
...
def is_instance(self, input_data: Any) -> bool:
...
def is_instance_json(self, input_data: str | bytes | bytearray) -> bool:
...
def json_schema(self) -> dict:
...
def dump(
self,
data: ValidData,
include: ... = None,
exclude: ... = None,
by_alias: bool = False,
exclude_unset: bool = False,
exclude_defaults: bool = False,
exclude_none: bool = False,
mode: Literal['unchanged', 'dicts', 'json-compliant'] = 'unchanged',
converter: Callable[[Any], Any] | None = None
) -> Any:
...
def dump_json(self, ...) -> str:
...
```
This could be used directly, but more commonly will be used by the following:
- `BaseModel`
- the `validate` decorator described above
- `pydantic.dataclasses.dataclass` (which might be an alias of `validate`)
- generics
The aim will be to get pydantic V2 to a place were the vast majority of tests continue to pass unchanged.
Thereby guaranteeing (as much as possible) that the external interface to pydantic and its behaviour are unchanged.
## Conversion Table :material-table:
The table below provisionally defines what input value types are allowed to which field types.
**An updated and complete version of this table is available in [V2 conversion table](https://docs.pydantic.dev/latest/concepts/conversion_table/)**.
:::note
Some type conversion shown here is a significant departure from existing behavior, we may have to provide a config flag for backwards compatibility for a few of them, however pydantic V2 cannot be entirely backward compatible, see [pydantic-core#152](https://github.com/pydantic/pydantic-core/issues/152).
:::
| Field Type | Input | Mode | Input Source | Conditions |
| ------------- | ----------- | ------ | ------------ | --------------------------------------------------------------------------- |
| `str` | `str` | both | python, JSON | - |
| `str` | `bytes` | lax | python | assumes UTF-8, error on unicode decoding error |
| `str` | `bytearray` | lax | python | assumes UTF-8, error on unicode decoding error |
| `bytes` | `bytes` | both | python | - |
| `bytes` | `str` | both | JSON | - |
| `bytes` | `str` | lax | python | - |
| `bytes` | `bytearray` | lax | python | - |
| `int` | `int` | strict | python, JSON | max abs value 2^64 - `i64` is used internally, `bool` explicitly forbidden |
| `int` | `int` | lax | python, JSON | `i64` |
| `int` | `float` | lax | python, JSON | `i64`, must be exact int, e.g. `f % 1 == 0`, `nan`, `inf` raise errors |
| `int` | `Decimal` | lax | python, JSON | `i64`, must be exact int, e.g. `f % 1 == 0` |
| `int` | `bool` | lax | python, JSON | - |
| `int` | `str` | lax | python, JSON | `i64`, must be numeric only, e.g. `[0-9]+` |
| `float` | `float` | strict | python, JSON | `bool` explicitly forbidden |
| `float` | `float` | lax | python, JSON | - |
| `float` | `int` | lax | python, JSON | - |
| `float` | `str` | lax | python, JSON | must match `[0-9]+(\.[0-9]+)?` |
| `float` | `Decimal` | lax | python | - |
| `float` | `bool` | lax | python, JSON | - |
| `bool` | `bool` | both | python, JSON | - |
| `bool` | `int` | lax | python, JSON | allowed: `0, 1` |
| `bool` | `float` | lax | python, JSON | allowed: `0, 1` |
| `bool` | `Decimal` | lax | python, JSON | allowed: `0, 1` |
| `bool` | `str` | lax | python, JSON | allowed: `'f', 'n', 'no', 'off', 'false', 't', 'y', 'on', 'yes', 'true'` |
| `None` | `None` | both | python, JSON | - |
| `date` | `date` | both | python | - |
| `date` | `datetime` | lax | python | must be exact date, eg. no H, M, S, f |
| `date` | `str` | both | JSON | format `YYYY-MM-DD` |
| `date` | `str` | lax | python | format `YYYY-MM-DD` |
| `date` | `bytes` | lax | python | format `YYYY-MM-DD` (UTF-8) |
| `date` | `int` | lax | python, JSON | interpreted as seconds or ms from epoch, see [speedate], must be exact date |
| `date` | `float` | lax | python, JSON | interpreted as seconds or ms from epoch, see [speedate], must be exact date |
| `datetime` | `datetime` | both | python | - |
| `datetime` | `date` | lax | python | - |
| `datetime` | `str` | both | JSON | format `YYYY-MM-DDTHH:MM:SS.f` etc. see [speedate] |
| `datetime` | `str` | lax | python | format `YYYY-MM-DDTHH:MM:SS.f` etc. see [speedate] |
| `datetime` | `bytes` | lax | python | format `YYYY-MM-DDTHH:MM:SS.f` etc. see [speedate], (UTF-8) |
| `datetime` | `int` | lax | python, JSON | interpreted as seconds or ms from epoch, see [speedate] |
| `datetime` | `float` | lax | python, JSON | interpreted as seconds or ms from epoch, see [speedate] |
| `time` | `time` | both | python | - |
| `time` | `str` | both | JSON | format `HH:MM:SS.FFFFFF` etc. see [speedate] |
| `time` | `str` | lax | python | format `HH:MM:SS.FFFFFF` etc. see [speedate] |
| `time` | `bytes` | lax | python | format `HH:MM:SS.FFFFFF` etc. see [speedate], (UTF-8) |
| `time` | `int` | lax | python, JSON | interpreted as seconds, range 0 - 86399 |
| `time` | `float` | lax | python, JSON | interpreted as seconds, range 0 - 86399.9\* |
| `time` | `Decimal` | lax | python, JSON | interpreted as seconds, range 0 - 86399.9\* |
| `timedelta` | `timedelta` | both | python | - |
| `timedelta` | `str` | both | JSON | format ISO8601 etc. see [speedate] |
| `timedelta` | `str` | lax | python | format ISO8601 etc. see [speedate] |
| `timedelta` | `bytes` | lax | python | format ISO8601 etc. see [speedate], (UTF-8) |
| `timedelta` | `int` | lax | python, JSON | interpreted as seconds |
| `timedelta` | `float` | lax | python, JSON | interpreted as seconds |
| `timedelta` | `Decimal` | lax | python, JSON | interpreted as seconds |
| `dict` | `dict` | both | python | - |
| `dict` | `Object` | both | JSON | - |
| `dict` | `mapping` | lax | python | must implement the mapping interface and have an `items()` method |
| `TypedDict` | `dict` | both | python | - |
| `TypedDict` | `Object` | both | JSON | - |
| `TypedDict` | `Any` | both | python | builtins not allowed, uses `getattr`, requires `from_attributes=True` |
| `TypedDict` | `mapping` | lax | python | must implement the mapping interface and have an `items()` method |
| `list` | `list` | both | python | - |
| `list` | `Array` | both | JSON | - |
| `list` | `tuple` | lax | python | - |
| `list` | `set` | lax | python | - |
| `list` | `frozenset` | lax | python | - |
| `list` | `dict_keys` | lax | python | - |
| `tuple` | `tuple` | both | python | - |
| `tuple` | `Array` | both | JSON | - |
| `tuple` | `list` | lax | python | - |
| `tuple` | `set` | lax | python | - |
| `tuple` | `frozenset` | lax | python | - |
| `tuple` | `dict_keys` | lax | python | - |
| `set` | `set` | both | python | - |
| `set` | `Array` | both | JSON | - |
| `set` | `list` | lax | python | - |
| `set` | `tuple` | lax | python | - |
| `set` | `frozenset` | lax | python | - |
| `set` | `dict_keys` | lax | python | - |
| `frozenset` | `frozenset` | both | python | - |
| `frozenset` | `Array` | both | JSON | - |
| `frozenset` | `list` | lax | python | - |
| `frozenset` | `tuple` | lax | python | - |
| `frozenset` | `set` | lax | python | - |
| `frozenset` | `dict_keys` | lax | python | - |
| `is_instance` | `Any` | both | python | `isinstance()` check returns `True` |
| `is_instance` | - | both | JSON | never valid |
| `callable` | `Any` | both | python | `callable()` check returns `True` |
| `callable` | - | both | JSON | never valid |
The `ModelClass` validator (use to create instances of a class) uses the `TypedDict` validator, then creates an instance
with `__dict__` and `__fields_set__` set, so same rules apply as `TypedDict`.
[speedate]: https://docs.rs/speedate/latest/speedate/
[check]: /assets/blog/icons/check.svg
[x]: /assets/blog/icons/x.svg0:["XkuJK-COl1nyJZB3ydOeT",[[["",{"children":["articles",{"children":["__PAGE__",{}]}]},"$undefined","$undefined",true],["",{"children":["articles",{"children":["__PAGE__",{},[["$L1",[["$","section",null,{"className":"bg-purple-light","children":["$","div",null,{"className":"container relative","children":[["$","div",null,{"className":"grid-l"}],["$","div",null,{"className":"grid-r"}],["$","div",null,{"className":"w-full px-[10px] py-[40px] text-center md:py-[90px]","children":["$","h1",null,{"className":"text-58 text-petroleum","children":"Pydantic Blog"}]}]]}]}],["$","$L2",null,{"posts":[{"date":"2025-07-02T09:00:00.000Z","slug":"q2-2025-summary","title":"Dashboards, MCP, Evals and more: Pydantic Update Q2 2025","description":"Pydantic AI and Logfire Q2 2025 Updates","ogImage":"","readtime":"4 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"}],"categories":["Pydantic","Logfire","Company"],"content":"$3"},{"date":"2025-05-28T09:00:00.000Z","slug":"building-data-team-with-pydanticai","title":"Guest Post: Building a Data Team that Never Sleeps with Pydantic AI","description":"","ogImage":"","readtime":"10 mins","authors":[{"name":"Nic"}],"categories":["Logfire"],"content":"$4"},{"date":"2025-04-02T09:00:00.000Z","slug":"q1-2025-summary","title":"The Eval has landed 🦅","description":"Pydantic Q1 2025 Product Updates","ogImage":"","readtime":"4 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"}],"categories":["Pydantic","Logfire","Company"],"content":"$5"},{"date":"2025-03-27T00:00:00.000Z","slug":"pydantic-v2-11-release","title":"Pydantic v2.11","description":"Pydantic v2.11 release highlights","ogImage":"","readtime":"15 mins","categories":["Release","Performance Improvements","New Features"],"authors":[{"name":"Sydney Runkle","picture":"https://avatars.githubusercontent.com/u/54324534"},{"name":"Victorien Plot","picture":"https://avatars.githubusercontent.com/u/65306057"}],"content":"$6"},{"date":"2025-03-26T09:00:00.000Z","slug":"eu-region-launch","title":"Pydantic Logfire EU Data Region Announcement","description":"Logfire now offers data residency in the EU region","ogImage":"","readtime":"2 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"}],"categories":["Logfire","Company"],"content":"$7"},{"date":"2025-03-24T09:00:00.000Z","slug":"js-sdk-launch","title":"Pydantic Logfire JavaScript SDK Announcement","description":"Our Logfire JavaScript & TypeScript SDK Is Now Available","ogImage":"","readtime":"2 mins","authors":[{"name":"Petyo Ivanov","picture":"https://avatars.githubusercontent.com/u/13347"}],"categories":["Logfire","Company"],"content":"$8"},{"date":"2025-03-21T09:00:00.000Z","slug":"logfire-self-hosting-announcement","title":"Pydantic Logfire Enterprise","description":"Logfire Self Hosting Is Available","ogImage":"","readtime":"5 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"}],"categories":["Logfire","Company"],"content":"$9"},{"date":"2025-03-20T09:00:00.000Z","slug":"mcp-launch","title":"PydanticAI MCP Support & Logfire MCP Server Announcement","description":"Connect to the Logfire MCP server for easy debugging","ogImage":"","readtime":"2 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"}],"categories":["Logfire","Company"],"content":"$a"},{"date":"2025-03-19T09:00:00.000Z","slug":"rust-sdk-launch","title":"Pydantic Logfire Rust SDK Announcement","description":"Our Logfire Rust SDK Is Now Available","ogImage":"","readtime":"2 mins","authors":[{"name":"David Hewitt","picture":"https://avatars.githubusercontent.com/u/1939362"}],"categories":["Logfire","Company"],"content":"$b"},{"date":"2025-03-17T01:00:00.000Z","slug":"hiring-again","title":"Pydantic is Hiring Again","description":"The Pydantic team has new open roles","ogImage":"","readtime":"2 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"}],"categories":["Logfire","Company"],"content":"\nPydantic is hiring again! We are rapidly growing and have just opened the following roles:\n\n* [Open Source Developer](https://pydantic.dev/jobs/open_source_developer) to work on Pydantic & [PydanticAI](https://ai.pydantic.dev/) (amongst others).\n* [Platform Engineer](https://pydantic.dev/jobs/platform_engineer) to help us scale our [Logfire](https://pydantic.dev/logfire) observability platform.\n* [Frontend Engineer](https://pydantic.dev/jobs/frontend-engineer) to help us with deep frontend expertise.\n* [UI Engineer](https://pydantic.dev/jobs/ui-engineer) to help us with design & frontend.\n* [Rust / Database developer](https://pydantic.dev/jobs/rust) to work on our database, based on Apache DataFusion.\n\nIf you think what we're working on sounds interesting, please get in touch.\n"},{"date":"2024-11-13T00:00:00.000Z","slug":"pydantic-v2-10-release","title":"Pydantic v2.10","description":"","ogImage":"","readtime":"12 mins","categories":["Release","Performance Improvements","New Features"],"authors":[{"name":"Sydney Runkle","picture":"https://avatars.githubusercontent.com/u/54324534"}],"content":"$c"},{"date":"2024-10-10T00:00:00.000Z","slug":"why-hyperlint-chose-logfire-for-observability","title":"Why Hyperlint Chose Pydantic Logfire as Our Observability Provider","description":"","ogImage":"","authors":[{"name":"Bill Chambers","picture":"https://avatars.githubusercontent.com/u/1642503"}],"categories":["Observability","Pydantic Logfire"],"content":"$d"},{"date":"2024-10-07T00:00:00.000Z","title":"The Pydantic Open Source Fund","description":"Pydantic is investing in the open source projects that power what we do.","ogImage":"","readtime":"4 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"}],"categories":["Open Source","Company"],"slug":"pydantic-oss-fund-2024","content":"$e"},{"date":"2024-10-01T01:00:00.000Z","slug":"why-logfire","title":"Why is Pydantic building an Observability Platform?","description":"Why are the team behind Pydantic developing an observability platform?","ogImage":"","readtime":"8 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"}],"categories":["Logfire","Company"],"content":"$f"},{"date":"2024-10-01T00:00:00.000Z","slug":"logfire-announcement","title":"Logfire launch and Series A Announcement","description":"Logfire is leaving beta and we've raised Series A funding","ogImage":"","readtime":"2 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"}],"categories":["Logfire","Company"],"content":"$10"},{"date":"2024-09-05T00:00:00.000Z","slug":"pydantic-v2-9-release","title":"Pydantic v2.9","description":"","ogImage":"","readtime":"10 mins","categories":["Release","Performance Improvements","New Features"],"authors":[{"name":"Sydney Runkle","picture":"https://avatars.githubusercontent.com/u/54324534"}],"content":"$11"},{"date":"2024-07-01T00:00:00.000Z","slug":"pydantic-v2-8-release","title":"Pydantic v2.8","description":"","ogImage":"","readtime":"10 mins","categories":["Release","Performance Improvements","New Features"],"authors":[{"name":"Sydney Runkle","picture":"https://avatars.githubusercontent.com/u/54324534"}],"content":"$12"},{"date":"2024-04-11T00:00:00.000Z","slug":"pydantic-v2-7-release","title":"New Features and Performance Improvements in Pydantic v2.7","description":"","ogImage":"","readtime":"10 mins","categories":["Release","Performance Improvements","New Features"],"authors":[{"name":"Sydney Runkle","picture":"https://avatars.githubusercontent.com/u/54324534"}],"content":"$13"},{"date":"2024-04-04T00:00:00.000Z","slug":"lambda-intro","title":"AWS Lambda Data Validation with Pydantic","description":"","ogImage":"","authors":[{"name":"Sydney Runkle","picture":"https://avatars.githubusercontent.com/u/54324534"}],"categories":["AWS Lambda","Serverless"],"content":"$14"},{"date":"2024-02-29T00:00:00.000Z","title":"Building a product search API with GPT-4 Vision, Pydantic, and FastAPI","description":"","ogImage":"","authors":[{"name":"Jason Liu","picture":"https://avatars.githubusercontent.com/u/4852235"}],"categories":["LLMs"],"slug":"llm-vision","content":"$15"},{"date":"2024-01-18T00:00:00.000Z","slug":"llm-validation","title":"Minimize LLM Hallucinations with Pydantic Validators","description":"","ogImage":"","authors":[{"name":"Jason Liu","picture":"https://avatars.githubusercontent.com/u/4852235"}],"categories":["LLMs"],"content":"$16"},{"date":"2024-01-04T00:00:00.000Z","title":"Steering Large Language Models with Pydantic","description":"","ogImage":"","authors":[{"name":"Jason Liu","picture":"https://avatars.githubusercontent.com/u/4852235"}],"categories":["LLMs"],"slug":"llm-intro","content":"$17"},{"date":"2023-06-30T00:00:00.000Z","title":"Pydantic V2 Is Here!","description":"","ogImage":"","readtime":"2 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"},{"name":"Terrence Dorsey","picture":"https://avatars.githubusercontent.com/u/370316"}],"categories":["V2"],"slug":"pydantic-v2-final","content":"\nThe last few months have involved a whirlwind of work, and we're finally ready to announce to official release of\nPydantic V2!\n\n## Getting started with Pydantic V2\n\nTo get started with Pydantic V2, install it from PyPI:\n\n```bash\npip install -U pydantic\n```\n\nPydantic V2 is compatible with Python 3.8 and above.\n\nSee [the docs](https://docs.pydantic.dev/latest/) for examples of Pydantic at work.\n\n\n\n## Migration guide\n\nIf you are upgrading an existing project, you can use our extensive [migration guide](https://docs.pydantic.dev/latest/migration/) to understand\nwhat has changed.\n\nIf you do encounter any issues, please [create an issue in GitHub](https://github.com/pydantic/pydantic/issues/new?assignees=&labels=bug+V2%2Cunconfirmed&projects=&template=bug-v2.yml)\nusing the `bug V2` label.\nThis will help us to actively monitor and track errors, and to continue to improve the library’s performance.\n\nThank you for your support, and we look forward to your feedback.\n"},{"date":"2023-06-13T00:00:00.000Z","title":"Help Us Build Our Roadmap | Pydantic","description":"","ogImage":"","readtime":"15 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"}],"categories":["Company","Logfire"],"slug":"roadmap","content":"$18"},{"date":"2023-04-03T00:00:00.000Z","title":"Pydantic V2 Pre Release","description":"","ogImage":"","readtime":"8 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"},{"name":"Terrence Dorsey","picture":"https://avatars.githubusercontent.com/u/370316"}],"categories":["V2"],"slug":"pydantic-v2-alpha","content":"$19"},{"date":"2023-02-16T00:00:00.000Z","title":"Company Announcement | Pydantic","description":"","ogImage":"","readtime":"8 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"}],"categories":["Company"],"slug":"company-announcement","content":"$1a"},{"date":"2022-07-10T00:00:00.000Z","title":"Pydantic V2 Plan","description":"","ogImage":"","readtime":"25 mins","authors":[{"name":"Samuel Colvin","picture":"https://avatars.githubusercontent.com/u/4039449"}],"categories":["V2"],"slug":"pydantic-v2","content":"$1b"}],"categories":["Pydantic","Logfire","Company","Release","Performance Improvements","New Features","Observability","Pydantic Logfire","Open Source","AWS Lambda","Serverless","LLMs","V2"]}],["$","section",null,{"className":"bg-paraffin","children":["$","div",null,{"className":"container","children":["$","div",null,{"className":"border-x border-sugar/20 pt-10 md:py-[60px]","children":["$","div",null,{"className":"grid md:grid-cols-3","children":[["$","div",null,{"className":"relative flex aspect-[864/540] items-center justify-center text-center md:col-span-2","children":[["$","svg",null,{"xmlns":"http://www.w3.org/2000/svg","fill":"none","viewBox":"0 0 864 541","className":"absolute inset-0 z-0 h-full w-full","children":[["$","rect",null,{"width":"864","height":"540","transform":"translate(0 0.805664)","fill":"#300321"}],["$","path",null,{"d":"M1242.48 270.687L438.5 -533.293L-365.48 270.687L438.5 1074.67L1242.48 270.687Z","fill":"#C00C84","fillOpacity":"0.1"}],["$","path",null,{"d":"M1133.45 270.363L432 -431.087L-269.45 270.363L432 971.813L1133.45 270.363Z","fill":"#FCFFEC"}],["$","path",null,{"d":"M937.577 270.229L432 -235.349L-73.5772 270.229L432 775.806L937.577 270.229Z","fill":"#E520E9"}]]}],["$","div",null,{"className":"relative z-10 flex flex-col md:pt-2.5","children":[["$","h3",null,{"className":"text-70 max-w-[760px]","children":"Explore Logfire"}],["$","div",null,{"className":"mt-[34px] flex items-center justify-center gap-2","children":["$","a",null,{"href":"https://logfire.pydantic.dev","target":"_blank","className":"group relative inline-block overflow-hidden min-w-[9.75rem]","onMouseEnter":"$undefined","onMouseLeave":"$undefined","children":[["$","div",null,{"className":"btn h-full w-full duration-[400ms] group-hover:-translate-y-[101%] bg-paraffin text-white","children":["$","span",null,{"className":"block origin-bottom-left transition-transform duration-[400ms] group-hover:-rotate-3","children":"Get started"}]}],["$","div",null,{"aria-hidden":"true","className":"btn h-full w-full duration-[400ms] group-hover:-translate-y-[101%] bg-white text-paraffin absolute left-0 top-full","children":["$","span",null,{"className":"block origin-bottom-left transition-transform duration-[400ms] rotate-3 group-hover:rotate-0","children":"Get started"}]}]]}]}]]}]]}],["$","$L1c",null,{"href":"https://github.com/pydantic","target":"_blank","className":"group relative flex flex-col justify-between gap-6 overflow-hidden bg-[#3E042B] px-2.5 pt-12 text-white max-md:max-h-[230px] max-md:text-center md:gap-2 md:pr-0 md:pt-12 lg:pl-[65px] lg:pt-[65px]","children":[["$","div",null,{"className":"max-md:hidden","children":["$","div",null,{"className":"absolute right-0 top-0 z-10 flex size-16 items-center justify-center bg-lithium/20 text-lithium transition-colors group-hover:bg-lithium group-hover:text-white","children":["$","svg",null,{"xmlns":"http://www.w3.org/2000/svg","fill":"none","viewBox":"0 0 29 28","className":"size-7","children":["$","path",null,{"stroke":"currentColor","strokeWidth":"1.925","d":"M8.308 6.514h13.611v13.612M21.92 6.514 6.265 22.168"}]}]}]}],["$","p",null,{"className":"text-18-mono max-w-[200px] !leading-normal !tracking-[0.09px] max-md:mx-auto md:max-w-[250px]","children":["Explore our"," ",["$","span",null,{"className":"text-lithium underline transition-colors group-hover:text-lithium/80","children":"open source"}]," ","packages"]}],["$","$L1d",null,{"src":"/assets/footer/cta.svg","width":367,"height":335,"alt":"Product shot","className":"mx-auto transition-transform duration-500 group-hover:translate-y-2 md:mr-0 md:w-[80%] lg:w-full"}]]}]]}]}]}]}]]],null],null]},["$","$L1e",null,{"parallelRouterKey":"children","segmentPath":["children","articles","children"],"error":"$undefined","errorStyles":"$undefined","errorScripts":"$undefined","template":["$","$L1f",null,{}],"templateStyles":"$undefined","templateScripts":"$undefined","notFound":"$undefined","notFoundStyles":"$undefined","styles":null}],null]},[["$","html",null,{"lang":"en","className":"__variable_9a5b5d __variable_6acd15 __variable_2a2340 __variable_a148ac","children":[["$","head",null,{"children":[["$","link",null,{"rel":"apple-touch-icon","sizes":"180x180","href":"/favicon/apple-touch-icon.png"}],["$","link",null,{"rel":"icon","type":"image/png","sizes":"32x32","href":"/favicon/favicon-32x32.png"}],["$","link",null,{"rel":"icon","type":"image/png","sizes":"16x16","href":"/favicon/favicon-16x16.png"}],["$","link",null,{"rel":"manifest","href":"/favicon/site.webmanifest"}],["$","link",null,{"rel":"mask-icon","href":"/favicon/safari-pinned-tab.svg","color":"#000000"}],["$","link",null,{"rel":"shortcut icon","href":"/favicon/favicon.ico"}],["$","meta",null,{"name":"msapplication-TileColor","content":"#000000"}],["$","meta",null,{"name":"msapplication-config","content":"/favicon/browserconfig.xml"}],["$","meta",null,{"name":"theme-color","content":"#000"}],["$","link",null,{"rel":"alternate","type":"application/rss+xml","href":"/feed.xml"}]]}],["$","body",null,{"children":[["$","$L20",null,{}],["$","main",null,{"className":"pt-[60px] md:pt-[72px]","children":["$","$L1e",null,{"parallelRouterKey":"children","segmentPath":["children"],"error":"$undefined","errorStyles":"$undefined","errorScripts":"$undefined","template":["$","$L1f",null,{}],"templateStyles":"$undefined","templateScripts":"$undefined","notFound":["$","section",null,{"className":"flex min-h-[calc(100vh-72px)] items-center bg-paraffin py-12","children":["$","div",null,{"className":"container flex flex-col items-center space-y-8 sm:space-y-12","children":[["$","div",null,{"className":"flex w-full max-w-[42.5rem] items-center gap-x-6 sm:gap-x-9","children":[["$","svg",null,{"xmlns":"http://www.w3.org/2000/svg","width":"100%","height":"100%","viewBox":"0 0 156 205","fill":"none","className":"w-1/4","children":["$","path",null,{"d":"M99.9345 146.451H0V120.642L92.732 0H124.843V123.643H155.154V146.451H124.843V204.07H99.9345V146.451ZM99.9345 25.5088L25.2087 123.643H99.9345V25.5088Z","fill":"white"}]}],["$","div",null,{"className":"flex-1","children":["$","$21",null,{"fallback":null,"children":[["$","$L22",null,{"moduleIds":["app/not-found.tsx -> @/app/_components/globe/globe"]}],["$","$L23",null,{"className":"w-full"}]]}]}],["$","svg",null,{"xmlns":"http://www.w3.org/2000/svg","width":"100%","height":"100%","viewBox":"0 0 156 205","fill":"none","className":"w-1/4","children":["$","path",null,{"d":"M99.9345 146.451H0V120.642L92.732 0H124.843V123.643H155.154V146.451H124.843V204.07H99.9345V146.451ZM99.9345 25.5088L25.2087 123.643H99.9345V25.5088Z","fill":"white"}]}]]}],["$","div",null,{"className":"text-20-mono text-center text-white","children":"Sorry, this page cannot be found."}],["$","$L1c",null,{"href":"/","className":"btn btn-lithium sm:!mt-[3.75rem]","children":"Back to home"}]]}]}],"notFoundStyles":[],"styles":null}]}],["$","$L24",null,{}],["$","script",null,{"async":true,"src":"/flarelytics/client.js"}]]}]]}],null],null],[[["$","link","0",{"rel":"stylesheet","href":"/_next/static/css/fab6518cc982082e.css","precedence":"next","crossOrigin":"$undefined"}],["$","link","1",{"rel":"stylesheet","href":"/_next/static/css/a6cbf3812b89b809.css","precedence":"next","crossOrigin":"$undefined"}]],"$L25"]]]]
25:[["$","meta","0",{"name":"viewport","content":"width=device-width, initial-scale=1"}],["$","meta","1",{"charSet":"utf-8"}],["$","title","2",{"children":"Insights & product updates | Pydantic"}],["$","meta","3",{"name":"description","content":"Get the latest insights on the Pydantic blog, including product updates and our changelog."}],["$","meta","4",{"property":"og:title","content":"Insights & product updates | Pydantic"}],["$","meta","5",{"property":"og:description","content":"Get the latest insights on the Pydantic blog, including product updates and our changelog."}],["$","meta","6",{"property":"og:image","content":"https://pydantic.dev/articles/og.png"}],["$","meta","7",{"property":"og:image:alt","content":"Insights & product updates"}],["$","meta","8",{"name":"twitter:card","content":"summary_large_image"}],["$","meta","9",{"name":"twitter:title","content":"Insights & product updates | Pydantic"}],["$","meta","10",{"name":"twitter:description","content":"Get the latest insights on the Pydantic blog, including product updates and our changelog."}],["$","meta","11",{"name":"twitter:image","content":"https://pydantic.dev/articles/og.png"}],["$","meta","12",{"name":"twitter:image:alt","content":"Insights & product updates"}],["$","meta","13",{"name":"next-size-adjust"}]]
1:null