Many of you reading our recent Logfire launch and Series A Announcement may be wondering:
Wait, aren't you the team behind Pydantic, the data validation library? Why are you venturing into observability?
Fair question. Let me try to explain.
Frustrations with existing tools
I've been frustrated by existing logging and monitoring tools for years. Most of these tools are built to serve the needs of large enterprises, and the resulting complexity often outweighs the insights they provide.
In many ways, observability feels like it's stuck where the rest of infra was 15 years ago. The waves of innovation that have radically simplified the process of hosting a web application have largely passed observability by.
The recent surge of "Observability for AI" tools aren't much better — yes, observing LLM calls is important, even disproportionately so, but those LLM calls are ultimately just one part of your application. Why introduce a completely new tool for that, when we could have a single platform that effectively handles both AI-specific monitoring and traditional observability? That's why we built comprehensive AI observability into Logfire from day one.
Developer first Observability
What we need is a general purpose observability platform with first class support for AI — but most importantly, one that developers actually want to use. Developers are the ones interacting with observability tools the most, yet many platforms seem to forget this.
That's where our background building Pydantic comes into play. Pydantic didn't succeed because it was the first, or the fastest. It became ubiquitous because developers loved using it. We've carried that same focus on developer experience into Logfire, which, in the observability landscape, apparently makes us unusual.
To back this point up, it's tempting to list all of Logfire's features — but that already exists. Instead, I want to dive a little deeper into a few key choices we've made, as I think they are representative of the difference between Logfire and other observability tools.
The Logfire SDK
Maintaining good SDKs is a significant investment of both time and resources. Most observability startups have shifted to relying on OpenTelemetry (OTel), which supports multiple languages at a lower cost by avoiding the need to develop and maintain custom SDKs. While this makes business sense, the victim is the developer stuck struggling with low-level, verbose APIs that are frequently unpleasant to work with.
Because of this, for Logfire, relying solely on OTel's Python libraries was never an option.
Instead, we built a beautiful SDK that wraps OTel but provides a much nicer API, and includes features the bare OTel libraries will never offer.
import logfire
# this is generally all you need to set up logfire
logfire.configure()
# send a zero-duration span AKA a log
logfire.info("hello {name}", name="world")
# send a span with a duration
with logfire.span("my span"):
do_some_work()
# instrument a FastAPI app
app = FastAPI()
logfire.instrument_fastapi(app)
To contrast that with raw OTel, here's a working example of the same code using the Logfire SDK and the OTel SDK directly (including 36 lines of OTel boilerplate!).
Learn more about our SDK in the docs.
So far we only have a Logfire-specific SDK for Python, although you can send data to Logfire from any language with an OTel SDK today. But we plan to build Logfire SDKs for other languages soon, likely starting with our preferred stack of TypeScript, Python, and Rust.
SQL
The Logfire platform lets you write arbitrary SQL to query your data; you can use it to find attributes for a specific span, define alert conditions, or build complex aggregations for dashboards.
SELECT attributes->'result'->>'name' AS name,
EXTRACT(YEAR FROM (attributes->'result'->>'dob')::date) AS "birth year"
FROM records
WHERE attributes->'result'->>'country_code' = 'USA';
Allowing direct SQL access imposes real technical constraints on the databases we can use, and comes with big engineering challenges, which is why no other observability company supports it. But for developers, this flexibility is invaluable — and we think the trade-off is well worth it.
Again, like maintaining an SDK, this is a decision that would only be made in a company composed of people who write code most days.
Traces as Logs
One of the most innovative parts of Logfire is our live view:
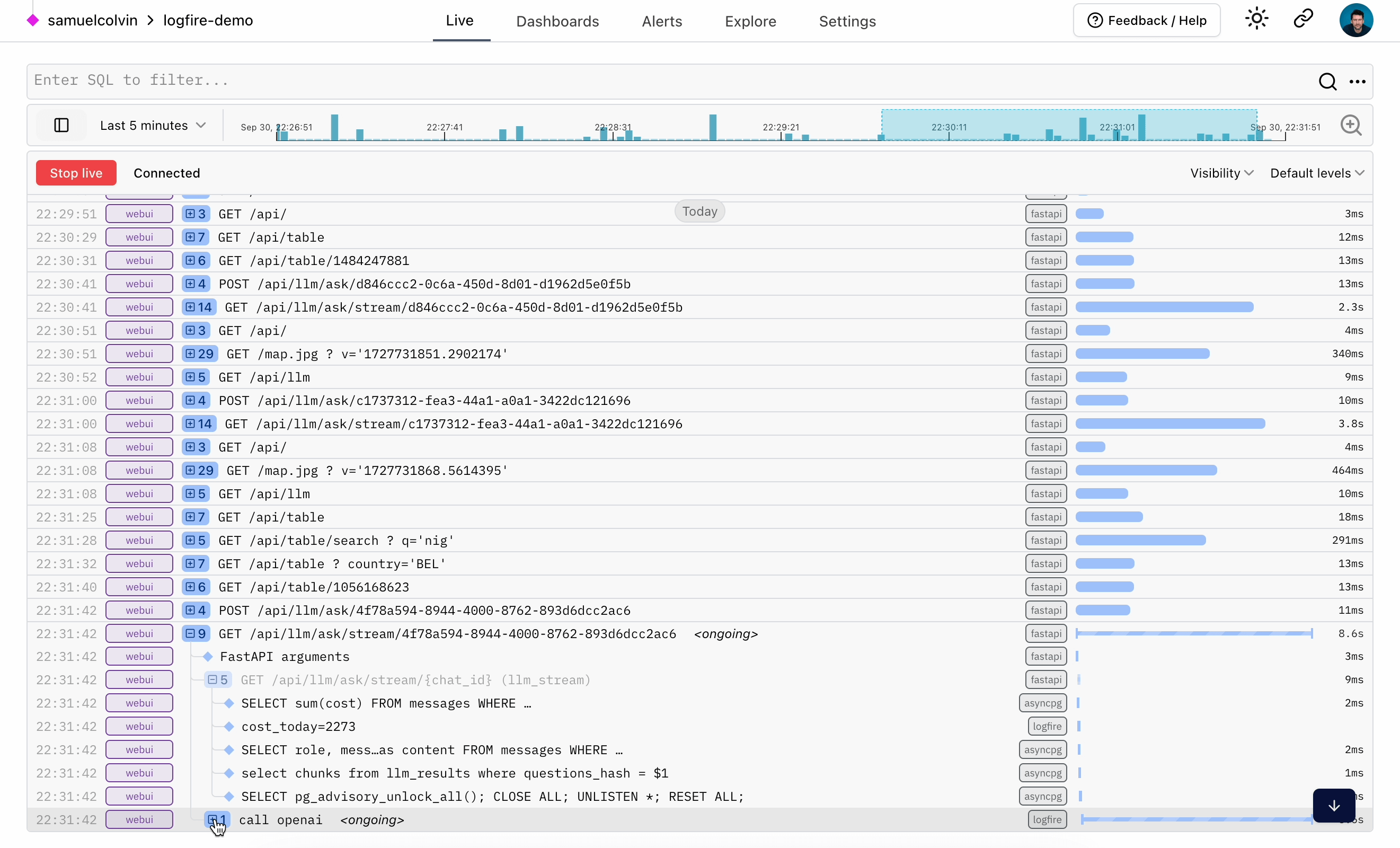
The data comes from OTel traces, but is displayed like logs, only better.
The problem with "standard" OTel data for this view is that spans aren't sent until they are finished, which means you can't see activity as it happens, and you can't properly contextualize child spans when you do receive them because you won't have their parent. By maintaining our own SDK, we've been able to enhance how OpenTelemetry works, so we can send data about spans when they begin — what we call a "pending span." This required substantial effort, but it results in a vastly improved developer experience for interactive workflows. Now, the live view truly feels live.
How we think about open source vs. commercial
Too many observability companies are abusing the open source label with their products. These products can be deliberately difficult to self-host to encourage use of the hosted alternative. In addition, the "open-source" versions are often missing critical functionality, forcing users onto closed source paid plans once they're locked in.
We're different: we have real, truly open source, open source, with massive adoption — Pydantic.
With Logfire, we're transparent: the SDK is open source (MIT licensed), but the platform itself is closed source. While we offer a generous free tier, our goal is for you to find enough value in Logfire to eventually pay for it. It's not always the simplest business decision, but we believe this transparency is the right approach.
Try logfire today if you haven't already
Logfire is still evolving, and it's far from perfect. But I believe it's fundamentally different from the tools that came before it, and it has the potential to change how developers understand their applications. And I believe it's already the best tool on the market for its job.
Please give it a try, and tell us what works, and what sucks.
P.S.: We're hiring:
- Open Source Developer to work on Pydantic & Pydantic AI (amongst others).
- Platform Engineer to help us scale our Pydantic Logfire observability platform.
- Frontend Engineer to help us with deep frontend expertise.
- UI Engineer to help us with design & frontend.
- Rust / Database developer to work on our database, based on Apache DataFusion.
If you think what we're working on sounds interesting, please get in touch.
