The following is a guest post from Definite
At Definite, we’ve built an AI agent (named "Fi") that is able to draw detailed insights from enormous amounts of data and do real data engineering work. Fi operates with high accuracy while keeping response times on the order of seconds. Our implementation supports recursion, multi-agent processes, model hot swapping, query validation, error correction, and file editing.
So how are we able to do this? How are we able to hot-swap models based on tasks, analyze each step of the thought process to ensure accuracy, identify latency bottlenecks, and show the real-time thought process of Fi?
Well, it took a lot of espresso. But we're also leveraging a powerful combination of: Pydantic, Pydantic AI, and Logfire.
Overview
All three of the above products are built by the same team behind the popular Pydantic, a python library that bundles many useful object-related operations with type-safe data structures. As for the other two tools, Pydantic AI is an agent framework, and Logfire is an agent-focused analytics platform.
Why Pydantic?
An AI agent framework is simply a protocol for structuring tools and LLMs programmatically to achieve some kind of desired user experience. At Definite, we selected the agent framework Pydantic AI for Fi because of the following:
- It’s the fastest, most modular, and most well documented framework we tested.
- It allows hot-swaps of models during agent instantiation.
- It allows hot-swaps of models during run instantiation.
- It allows hot-swaps of context by its “Deps” argument, reading context at-will (will expand on the importance of this later).
- It receives consistent attention from the team, indicating longevity.
- It allows “prepare” functions for each tool, meaning we can (and do) whitelist each tool based on soft or hard-coded criteria at will, eliminating opportunity for model distractions.
- It integrates well with Pydantic (widely used in our codebase) and Logfire (a performance-tracking product for latency and thought process).
- It enforces type safety on Tool input and output, allowing performance to be more predictable and explicit to design.
- It has street cred - it was created the same team behind Pydantic, an excellent type-enforcing package used in some of the biggest tech firms on the planet.
Breaking Ground
Setting up Pydantic AI is as simple as their documentation suggests, and in just a few lines an engineer can set up their first agent.
class MyModel(BaseModel):
city: str
country: str
model = os.getenv('PYDANTIC_AI_MODEL', 'openai:gpt-4o')
agent = Agent(model, output_type=MyModel, instrument=True)
result = agent.run_sync('The windy city in the US of A.')
We enforce the data structure in which it answers using Pydantic. In other words, this agent can only respond in the structure defined by a Pydantic model (‘MyModel’ in the example), ensuring predictable behavior from relatively unpredictable LLMs.
This is true both for our agent and each tool call, theoretically allowing us to hotswap any model + context + data structure by the run, making sure any call we make is not using a single token more than we need.
Engineering Challenges
Selective Context
For an agent to perform useful work across large amounts of context, it must intelligently query only relevant segments of data at any given time.
At Definite, we deal with terabytes of data at scale, so a simple agent + tool design ingesting our entire data source wouldn’t be good enough for our customers. To keep performance high and latency low, we first optimize for only the data relevant down to the specific task.
To properly implement this capability, we have 4 questions to answer:
- How do we track and benchmark performance of our model?
- How do we identify and eliminate latency bottlenecks?
- How do we query terabytes of data to draw useful insights in seconds?
- How do we build a system agnostic of any one model to switch when one surpasses another?
Benchmarking with Logfire
Rapid iteration is only useful if there are metrics and historical data that have some kind of statistical significance of an actual performance increase or lack thereof.
For this reason, we use Logfire, a tool that allows us to step through the thought process of our agent(s), seeing inferred inputs, outputs, token cost, and elapsed time at every step for ultimate optimization.
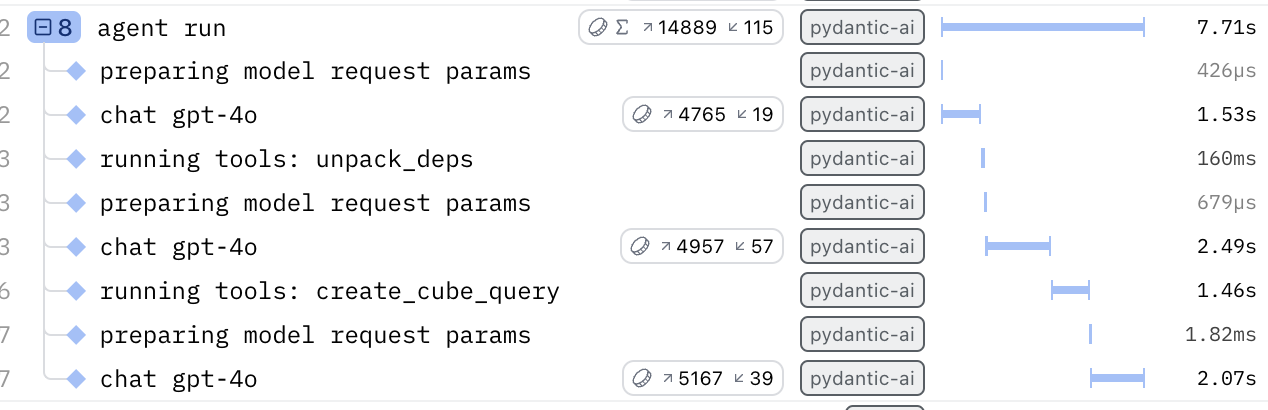
Some processes require a more capable but slower model, whereas others require a less capable but faster model. By using Logfire alongside our agent implementation, we can identify what is being called, when it is being called, and if we need to swap to another model for any particular tool.
Whitelisting
We have some 10+ tools and counting. Some tools incorporate another agent within them, whereas others are simple computation processes that we run to take some uncertainty out of our agent.
Regardless, having so many tools that rely on our agent to choose properly is a recipe for confusion and misunderstanding of the problem for the LLM. The ultimate achievement with proper agentic design is to supply the agent with as few decisions as possible. Telling the agent what tools to use and when to use them can dramatically increase performance and decrease decision time.
To do this programmatically, we leverage our prepare function for each tool during our instantiation of each. Our description tells the agent when to select the tool, the prepare function enables or disables it based on any criteria we’d like, and the execution function defined within each tool actually does the work we need.
This allows us to have a modular, cookie-cutter format for each tool we build, and it allows our agent to have information access on only a need-to-know basis.
Tool[Deps](
function=tool.execute,
prepare=allow_whitelist_tools,
name=tool.name,
description=str(tool.description[:1020]),
max_retries=4,
)
Schema Filtering
Data drives AI agents, but more is not better. In fact, more can mean less in this case, because having unnecessary data in a context window has two major (and very related) downfalls:
- Increased latency: Each context token that’s not needed but processed anyway during an agents’ solving will increase response times, always.
- Decreased performance: Having unnecessary data in a context window for an agent will only increase the likelihood of the model misunderstanding a question or going on a completely unrelated side quest to answer a question that was not asked.
For the amount of structure and design we put into AI agents, there still are some black-box elements to them. Any time engineers work with LLMs, they necessarily have to accept some degree of unknown behavior going on inside. That which makes agents powerful is precisely what makes them difficult to design well.
And for us, this problem is exaggerated. A Definite user’s data can be huge. We draw data from Stripe, Hubspot, Supabase, Posthog, and more into one data warehouse, so to draw insights based on a single query by stuffing all of these sources into one call would be catastrophically slow and likely not useful - not to mention, with the current state of the art, impossible.
Filtering
To address all three of these issues, we incorporate explicit and implicit filtering of each user’s schema. Then, we further trim the data by including only the metadata that are relevant to the question.
Explicit Filtering From User
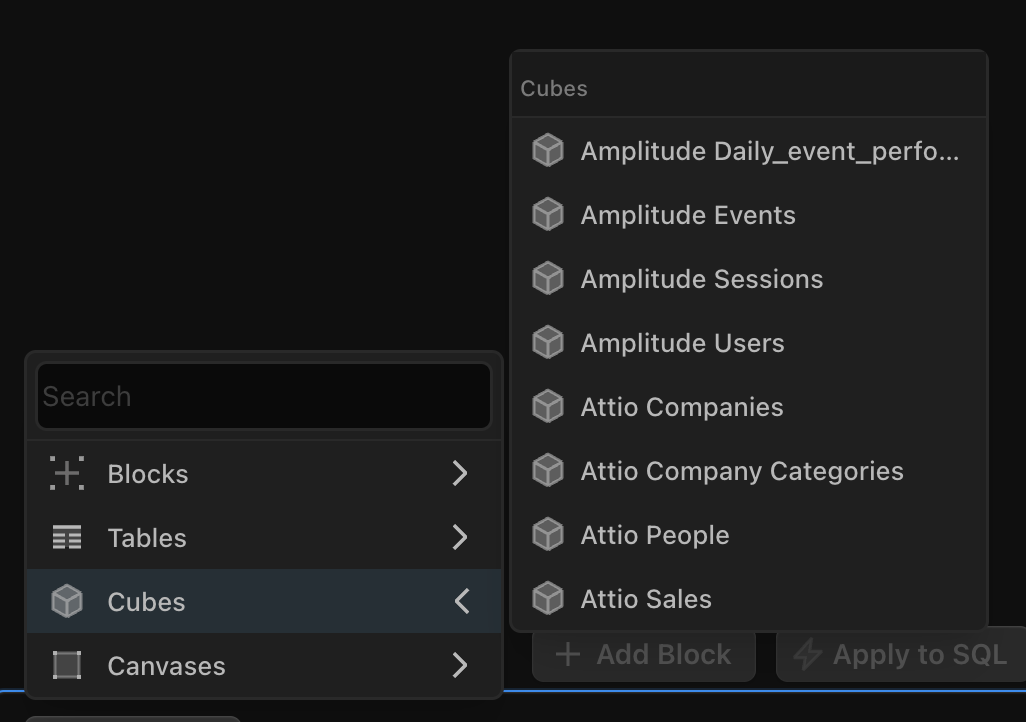
At every step, we aim to be as explicit as possible about the data that our agent ingests in pursuit of speeding up response times and making our responses as predictable as possible.
Implicit Filtering By Fi
If a user selects no data source, which is more common than the opposite, Fi implicitly selects the filters. But this isn’t done by feeding the data into Fi directly to filter - that would defeat the purpose. Instead, by feeding in the options of the filters themselves, along with relevant metadata like descriptions, measures, dimensions, etc, Fi can determine the relevant filters to apply, and then apply them to our data schema to in turn only get the relevant data.
Since our agent selects the filters for the data, we effectively cut the context window down by attacking the problem piece-wise.

When done properly, we keep our context windows tight, based on whatever patterns we know and can predict. And from that, we keep our agent on track and our latency on the order of seconds.
UX and Tool Calling
Good products nail the basics, but they must have more than that to become great products - they have to have something special.
Especially with data, we need to incorporate elements traditionally thought of as graphical user interfaces within our chat window itself.
These elements primarily include:
- Real-time updates on the agent’s thought process and steps.
- Rich data displays showing graphs and insights.
- Rich interactive data inputs rendered as UI elements within the chat.
And of course, our solution can’t be overfit for just these three challenges. We must design our system in such a way that any new user interface element we decide is necessary can easily be built and displayed. This includes elements already in our app that we’d like to conditionally render for convenience or for onboarding.
We’ll do it live! (with rich elements)
Since agents are fundamentally dozens, if not hundreds, of API calls to an LLM API, response times are not expected to be instant.
There are implementations that stream text, but this often increases technical complexity and doesn’t guarantee any speed increase anyway. Writing and reading to the database dozens of times for one message using a frontend subscription update can increase latency to the point that the cure is worse than the ailment.
As the industry has improved these text response times to make streaming obsolete, the new frontier exists in real-time updates on tool calling. Leading agentic apps - like Definite and Cursor, an AI development tool - use rich elements in addition to text for displaying data, providing updates to the user, and taking UI-driven inputs that wouldn’t otherwise come from a user’s natural language.
Cursor
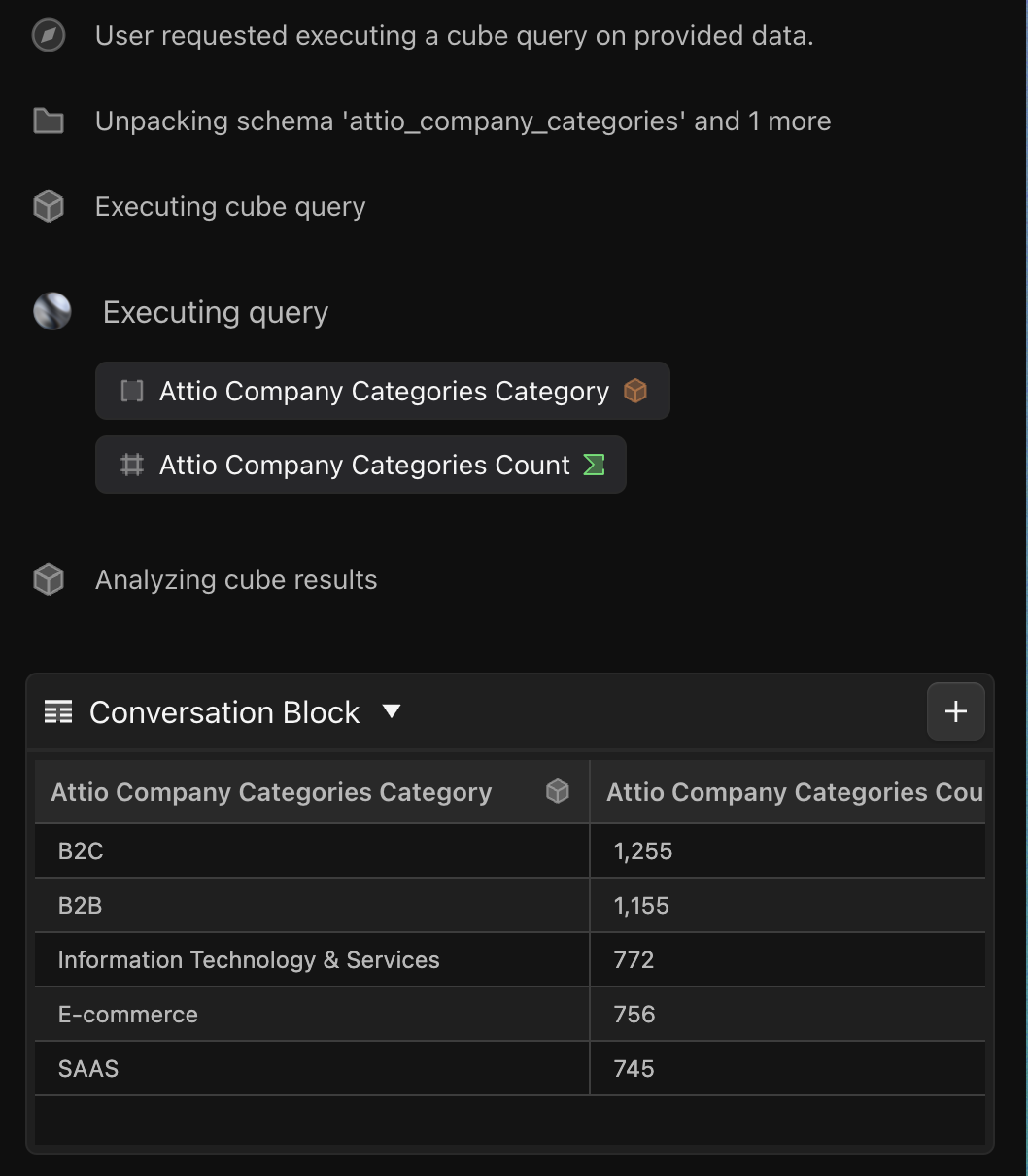
Definite
Since the standard for an agent’s chat interface is quickly changing, the standard for the user experience within the chat has risen higher than just text outputs and text area inputs. The future of agentic apps is not simply a conversation, but also rendering UI components embedded within agentic conversations that provide both rich display elements and fully featured, interactive user input components.
Challenges to Real-time display
One challenge for a unified conversation display is that the data objects that fuel Pydantic AI are different from those we use to display in the frontend. For instance, Pydantic AI uses custom ModelMessage objects containing different structures and fields from our initial frontend Message views.
ModelMessage = Annotated[Union[ModelRequest, ModelResponse], pydantic.Discriminator('kind')]
ModelMessages are used internally in Pydantic AI to keep message history in responding to previous messages. But every other UI element has a different structure, challenging the ability to cleanly render different elements within the same chat interface.
How then are we able to build a simple and scalable system that enables interfacing between different message data types, real-time updates, and rich content that is easily scalable as our customer demand grows?
Panels
Much like the beloved Python library Rich has a “Panel” object to vertically stack sections of data on top each other within the terminal interface, at Definite, we treat each type of update - Message, Form, Chart, Block - as its own type-agnostic entity, a “Panel”.
We wrap all elements within panels for display, while easily being able to parse by panel_type to select the elements we need for Pydantic’s message history in a simple database call as opposed to maintaining two collections of different types to read from.
ModelMessage = Annotated[Union[ModelRequest, ModelResponse], pydantic.Discriminator('kind')]
The above object is wrapped in a compatible format to be rendered with the rest of our rich content. And in our frontend, we have a lightweight “glue” function to sift through any structured payload within the panels to conditionally format and display in our chat interface.
class InfoPanel(BaseModel):
"""
A panel is a message in the thread.
"""
text: str
icon: Literal["cube", "play", "compass", "error", "folder", "table", "block", "sync"] = "play"
panel_type: Literal["info"] = "info"
class ModelMessagePanel(BaseModel):
"""
A wrapper for ModelMessage dataclass to use in Pydantic unions
"""
message: ModelMessage
panel_type: Literal["model"] = "model"
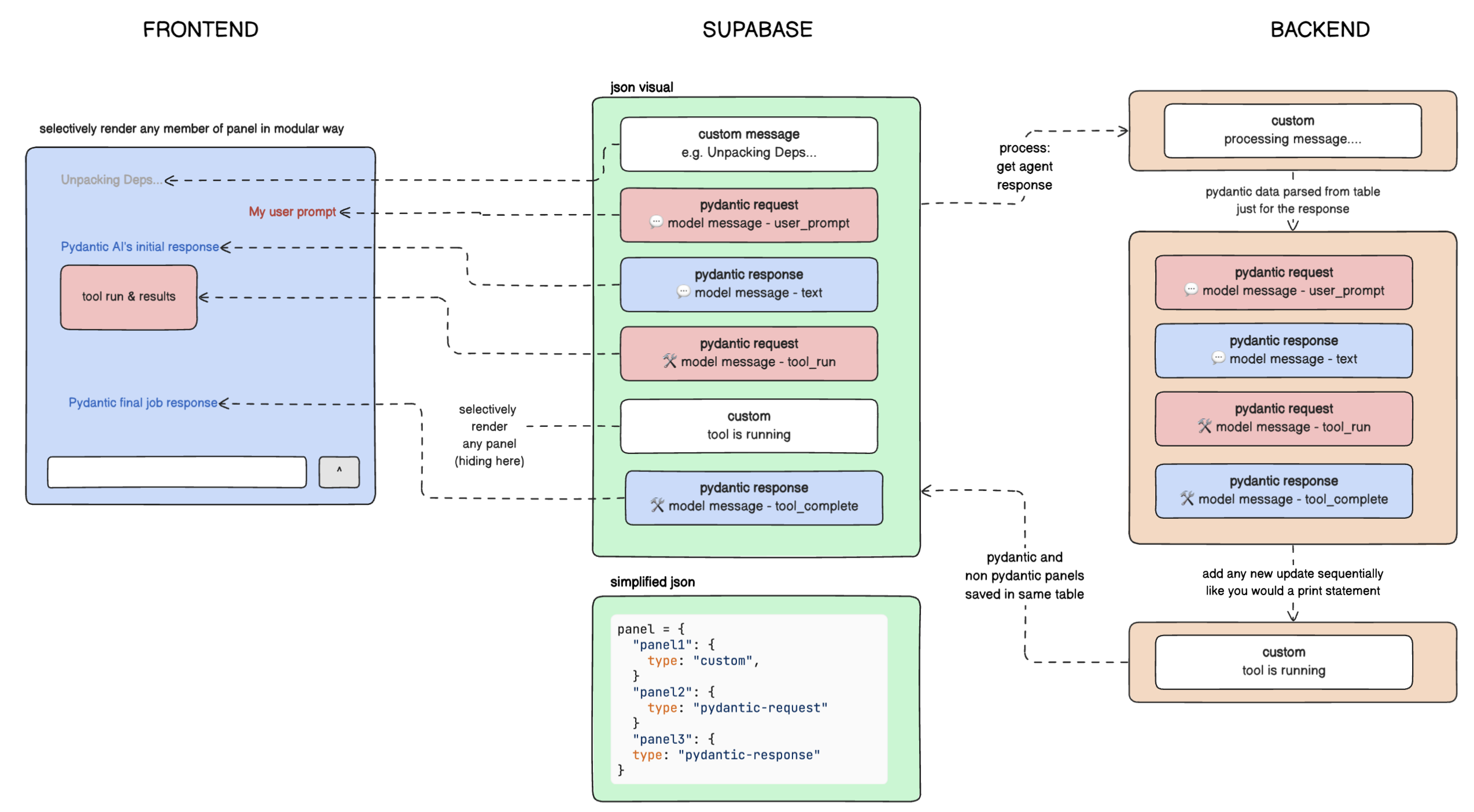
The end result of all of this theory is a powerful, simple, and scalable solution that supports real-time updates by simply listening to a thread object. Since we only read and write when there is a new panel, which is only every few seconds, response times become negligible.
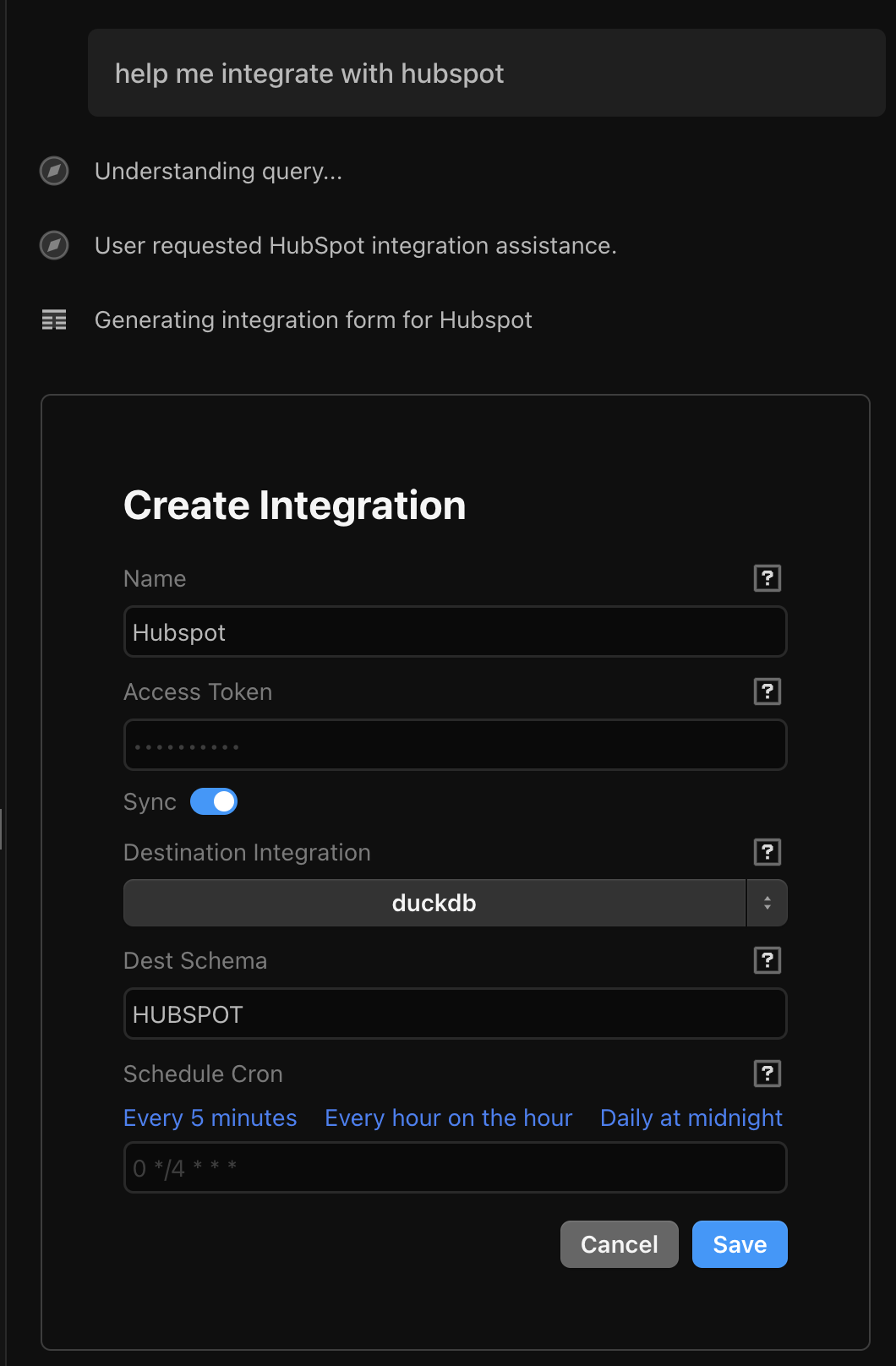
Google form-like, interactive forms
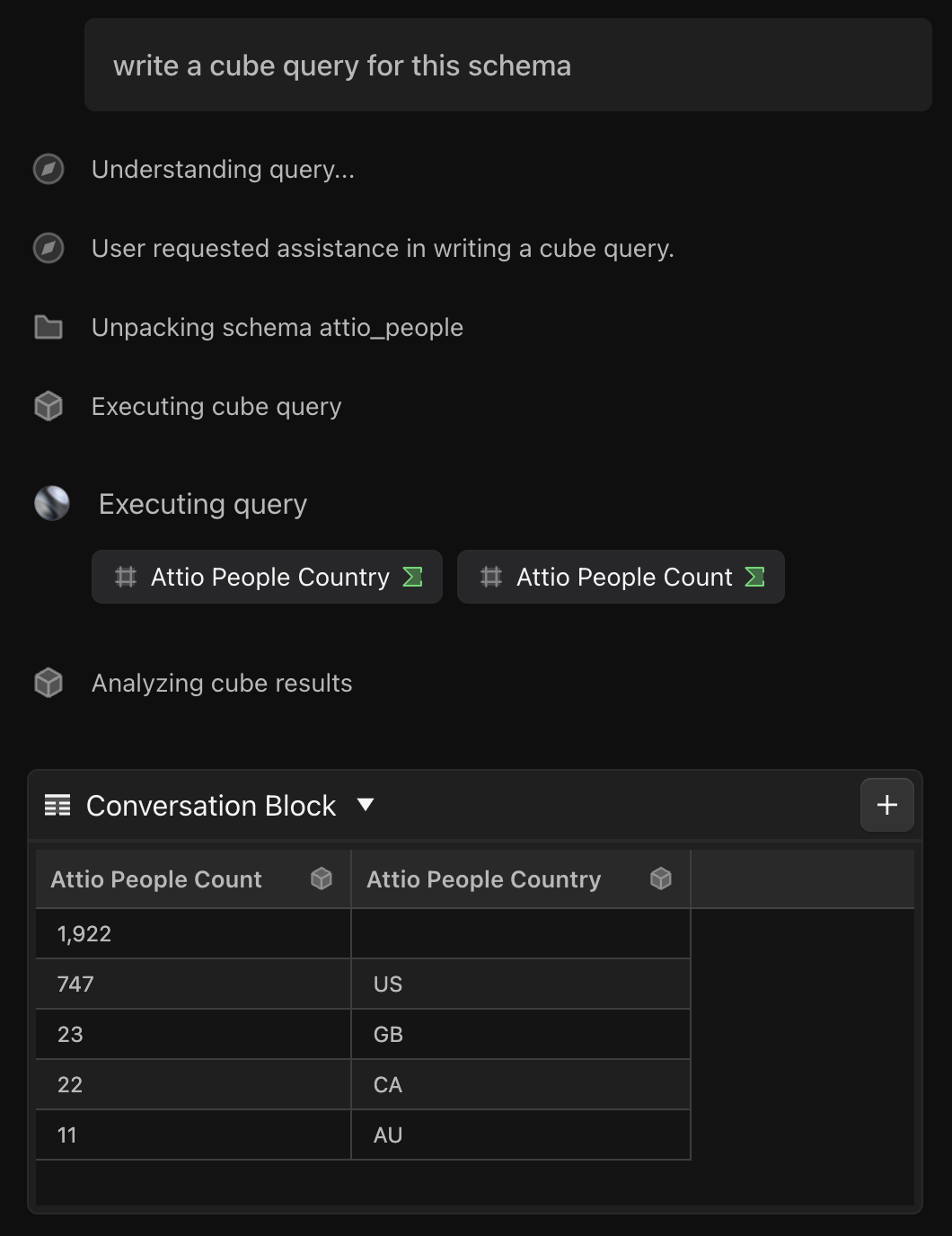
Excel-like, canvas-compatible blocks
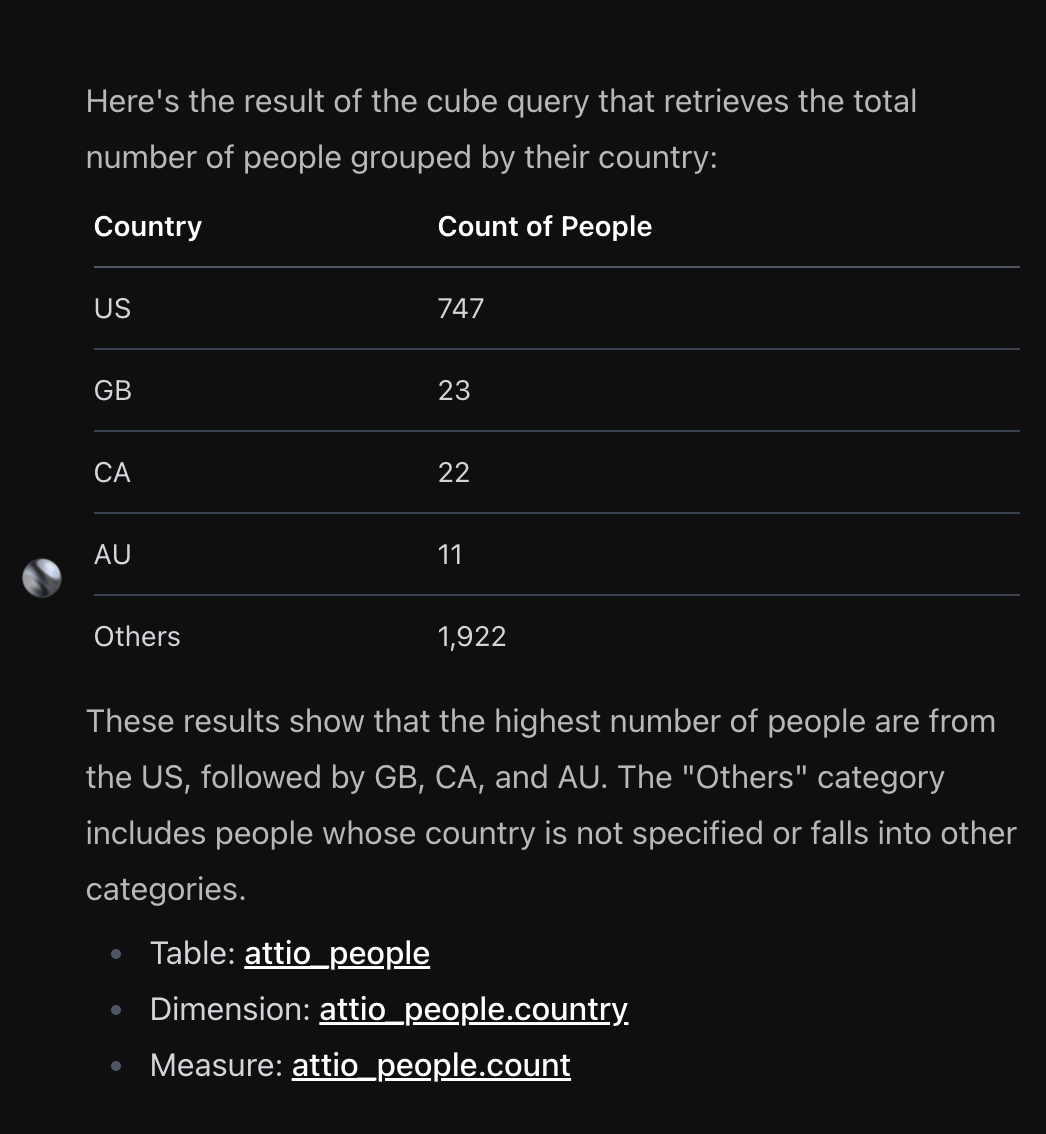
Full markdown support within chat
This infrastructure allows us to display many different types - perhaps every type - of UI element within the same, familiar, chat interface.
Real Time Introspection
There is a line between agents that are nice to have and agents that are catastrophic to lose. To cross that line, the agent needs to see the forest instead of the trees for tasks - perhaps even understanding the user’s question better than the user did when they asked it.
We approach this problem via negativa - instead of aiming for super intelligence, we aim to simply eliminate instances of tunnel vision through introspection on the tool level and introspection on the nested agent level.
Introspection Tool
Fi has a multi-agentic tool to actively error correct across its whole process. It can be thought of as an internal monologue within a single agent, calling whenever an error fires.
Since agents are fundamentally limited by being biased to the context they already have, we actually use two agents - our main Worker agent decides to call the error correction tool, and even gives a line of what it thinks may be happening, while a supporting agent within the tool takes what relevant information it has to solve the problem.
This process repeats as many times as the error repeats - or more realistically, as many times as the internal logic in the agent framework allows, where eventually the agent will solve the issue or determine it is hopeless. This flow is good for most applications, but can miss the point on edge cases because what may seem hopeless in the foxhole is not hopeless when surveying the entire area.
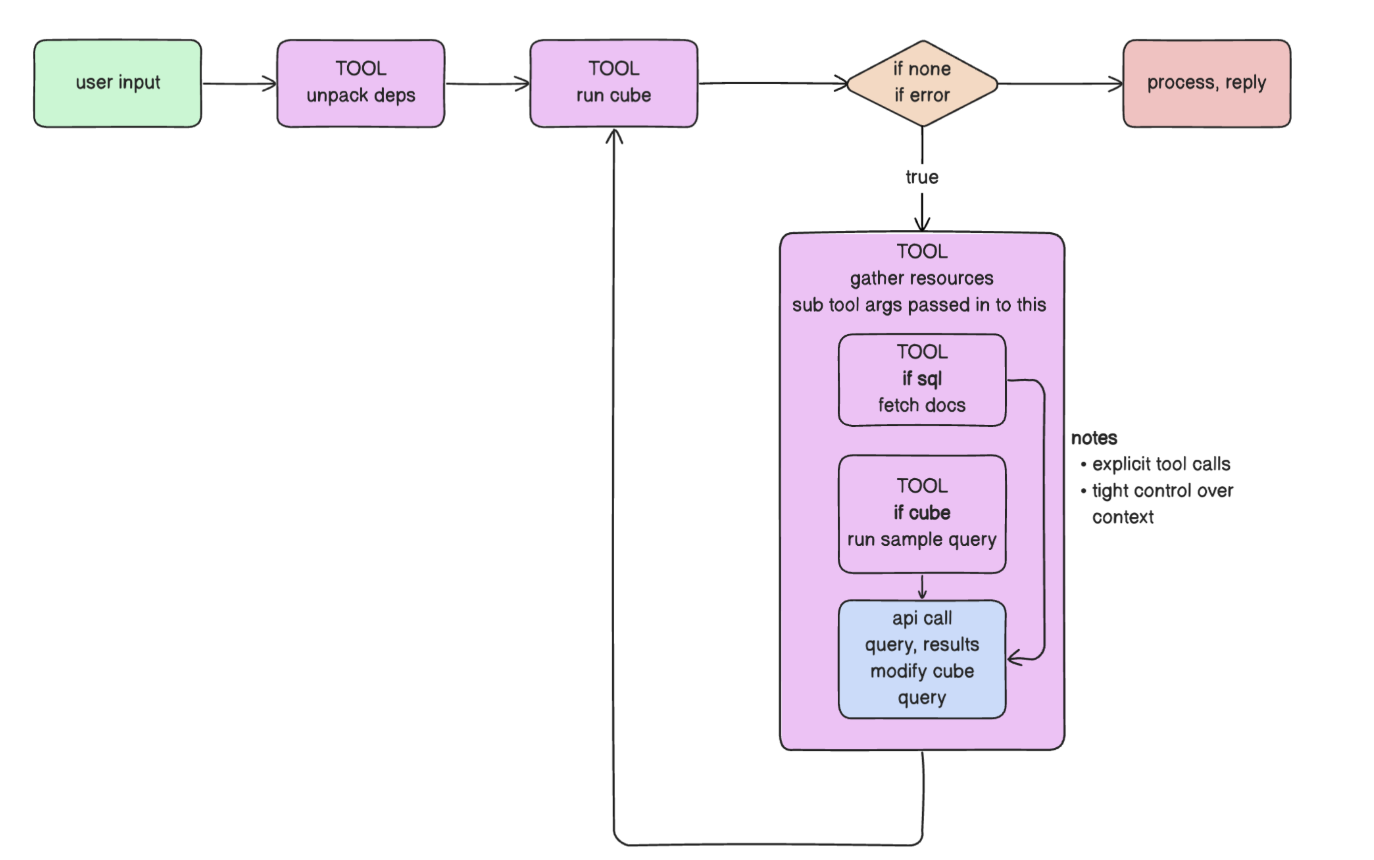
Introspection Agent
To remind and enforce our main Worker agent’s big-picture thinking, we use a Grader agent wrapped around it. Grader Fi is the customer’s liaison. It serves three purposes:
- Determine a list of system requirements at the beginning of the interaction that must be completed.
- Grade and reprompt the worker at the completion of each task.
- Grade all completed tasks to ensure they are either impossible to complete or have all been completed.
The optimization here is:
- How closely the list Grader creates matches the user’s intentions, often coming down to specificity.
- How well each worker can take each line and execute.
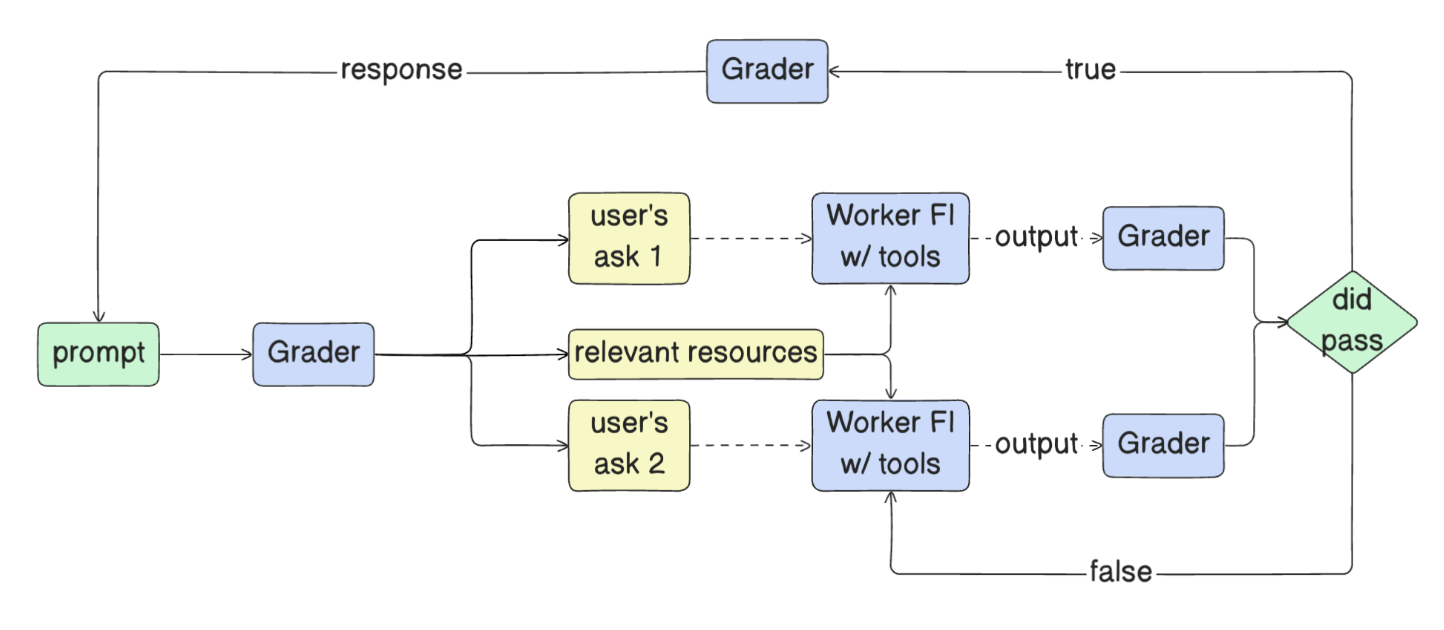
Though the simpler, and perhaps more accurate, optimization is more Turing-like:
- If Grader were not here, how similar are the prompts it gives to the Worker vs the prompts that a human might give to the Worker?
We’ve just released Grader Fi, and are already finding it expedite our customers’ experience in turning masses of data into actionable business insights.
Emergent
Emergent behavior is a phenomenon where a collection of very simple, predictable unit components working together create incredibly sophisticated, unpredictable systems.
Examples include ant colonies, bee hives, traffic intersections, cities, the stock market, supply chains, and three body problems. Already, products powered by properly built agentic systems are exhibiting these traits.
We’ve already seen emergent behavior in Fi in just the past few months, and will continue to see such improvement in the product and the industry as a whole.
Thanks for reading. If you want to try it out, you can ask Fi about your own data at definite.app.
