The following is a guest post from Hamza Tahir.
You have a Pydantic AI agent.
It has a model, a system prompt, a few tools, maybe a structured output type, and it works. On your laptop, the loop is easy to understand: the model thinks, calls a tool, reads the result, maybe calls another tool, then returns an answer.
from pydantic_ai import Agent
agent = Agent(
"openai:gpt-5.5",
name="researcher",
tools=[search_web, read_page, summarize],
system_prompt="Research the user's topic and return a concise brief.",
)
result = agent.run_sync("Find the most important news about AI infrastructure.")
print(result.output)
This is a good agent harness. It defines how the model is driven: which model to call, which tools it can use, what instructions it follows, and how the answer comes back.
Then you put it into production.
One URL times out. A pod gets evicted. The model already made six expensive calls before the seventh one failed. A human needs to approve the final action, but they are not online right now. The final answer exists somewhere in terminal output, but the intermediate decisions are gone. A coding assistant wants to inspect the failed run, but all you can give it is a pasted traceback.
The agent was real. The harness was good.
The missing piece was the runtime.
At Kitaru by ZenML, we build infrastructure for durable AI and ML workloads. We included a Pydantic AI adapter because we saw how common it was that developers were building useful agents but without a durable place to live once it left a notebook, local script, or single web request.
This post is about that boundary. Pydantic AI remains the agent harness. Kitaru by ZenML provides the runtime layer around it.
A great harness is not the same thing as a runtime
Pydantic AI is the part of the stack that helps you build the agent loop. It gives you a Pythonic way to define models, tools, dependencies, instructions, structured outputs, retries, and streaming.
But once an agent leaves a local script, a different set of questions appears:
- What remembers that
search_webalready succeeded? - What happens if
read_pagefails on the eighth URL? - Can we retry only the failed tool call?
- Can a human approve the next step without blocking a process?
- Can another agent inspect the run later through MCP?
- Where do the prompt, tool result, final answer, and failure artifact live?
- What happens if the machine running the agent disappears halfway through?
These are runtime questions.
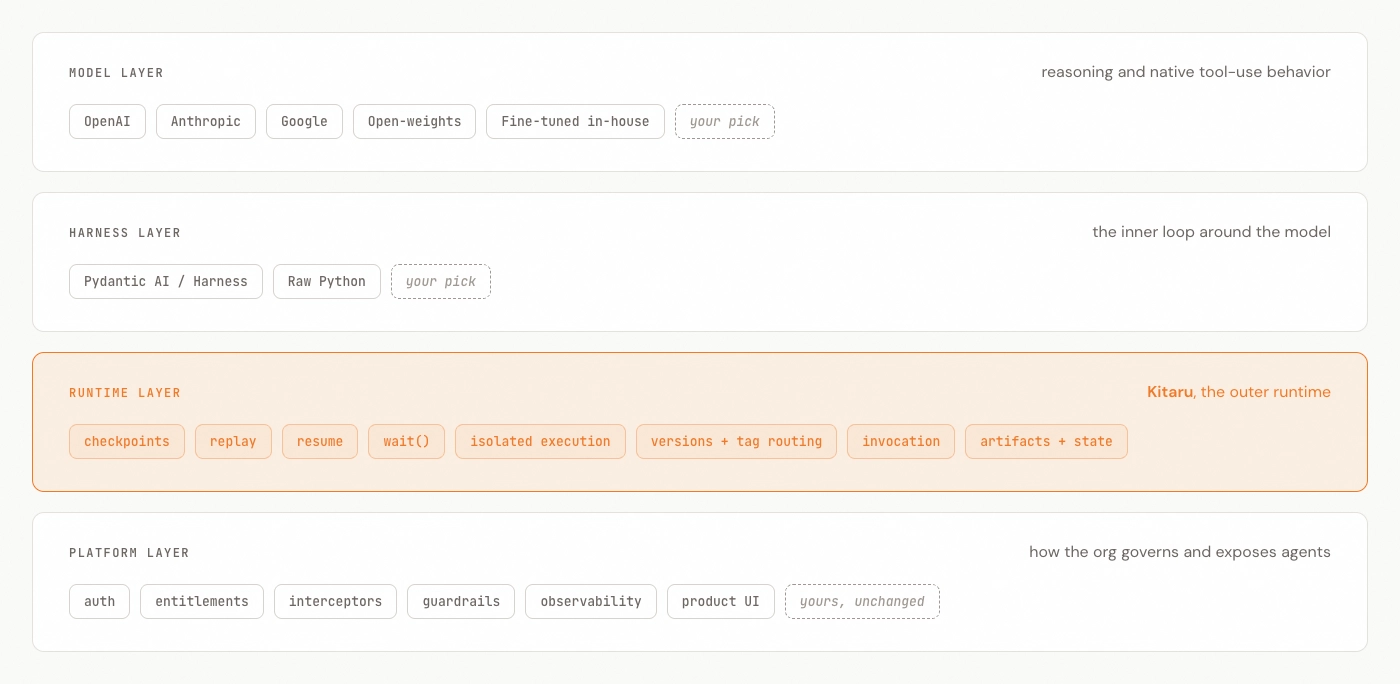
The agent stack has at least four layers:
The model is the thing generating tokens: OpenAI, Anthropic, Google, open weights, fine-tuned in-house models.
The harness is the loop around the model: prompts, tools, structured output, model calls, tool calls, retries, and streaming. Pydantic AI lives here.
The runtime is how the agent survives and executes over time: checkpoints, replay, resume, wait states, artifacts, execution history, versioned deployments, invocation routing, and execution placement. This is where Kitaru fits.
The platform is how the organization governs the system: auth, entitlements, policy, observability pipelines, product UI, approval workflows, and access control (RBAC and so on). Most companies already have parts of this before they ever deploy an agent.
So harnesses define agent behavior. Runtimes provide durable execution. Platforms define governance. This separation matters because most serious teams will not have exactly one harness. One team may use Pydantic AI. Another may use LangGraph. A third may use the OpenAI Agents SDK, Claude Agent SDK, or a raw Python loop.
If durability lives inside the harness, every team gets a different production story. If durability lives underneath the harness, the platform team can standardize on one runtime without forcing every app team to rewrite how their agents think.
What a runtime actually does
A runtime is the part of the system that still knows what happened after your Python process has moved on, crashed, paused, or restarted.
It knows which steps completed. It knows what they produced. It knows which step failed. It knows what input caused the failure. It knows where the run can resume. It gives humans, services, and other agents a durable object to inspect and operate.
That is the role we built Kitaru to play underneath a Pydantic AI agent.
Inside Kitaru, there is another split that matters:
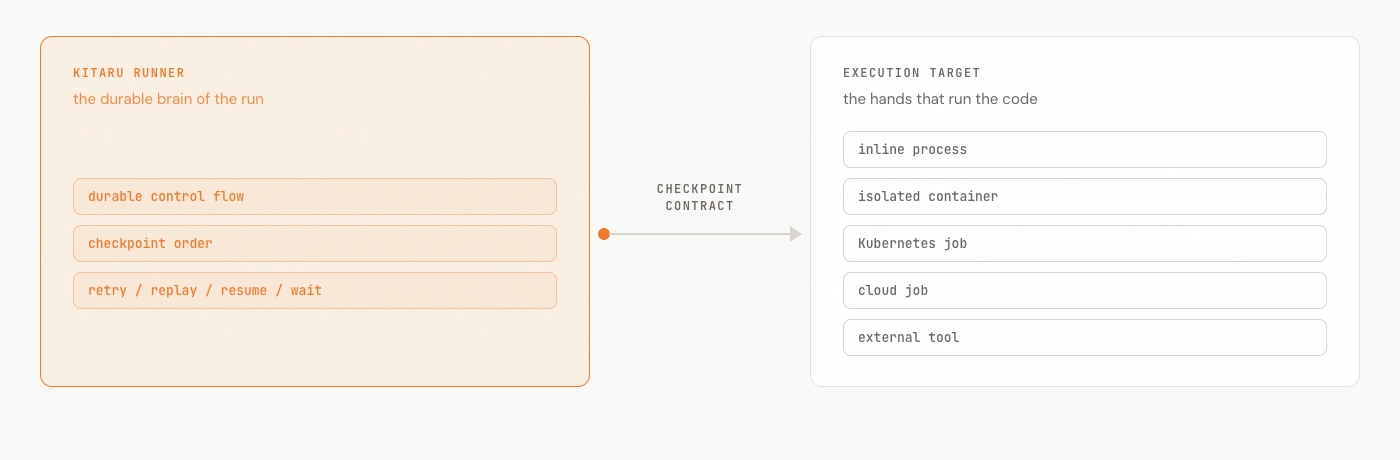
The runner is the durable brain of the run. It records checkpoint order, persists outputs, and handles retry, replay, resume, and wait states.
The execution target is the hands. It runs the actual code for a checkpoint: inline in the runner, in an isolated runtime, in a Kubernetes job, in a cloud job, or through an external tool.
Checkpoints are the contract between the brain and the hands.
If an execution target dies, the run should not forget who it is. The runner still has the save state. That is the operational difference between "my sandbox crashed" and "my whole agent run disappeared."
Wrapping Pydantic AI with Kitaru
Our integration is intentionally small. Pydantic AI keeps defining the agent loop. Kitaru wraps that loop in durable execution. PydanticAI provides a best-in-class abstraction around everything you need and want to build for an agent, so there’s no need to reinvent the wheel there.
from pydantic_ai import Agent
from kitaru.adapters.pydantic_ai import KitaruAgent
agent = Agent(
"openai:gpt-5.5",
name="researcher",
tools=[search_web, read_page, summarize],
system_prompt="Research the user's topic and return a concise brief.",
)
durable_agent = KitaruAgent(agent)
This also composes cleanly with Pydantic Logfire. If you already use Logfire to observe Pydantic AI runs, you can keep that instrumentation in place and add Kitaru underneath the same agent:
import logfire
from pydantic_ai import Agent
from kitaru.adapters.pydantic_ai import KitaruAgent
logfire.configure()
logfire.instrument_pydantic_ai()
agent = Agent(
"openai:gpt-5.5",
name="researcher",
tools=[search_web, read_page, summarize],
system_prompt="Research the user's topic and return a concise brief.",
)
durable_agent = KitaruAgent(agent)
Logfire gives you the trace: model calls, tool calls, latency, token usage, and errors. Kitaru gives the same run a durable operational shape: checkpoints, replay, resume, wait states, and artifacts.
For local experiments, KitaruAgent can auto-open a Kitaru flow around a run. For production-shaped workloads, we usually recommend making the flow boundary explicit, because the flow is the thing you deploy, invoke, inspect, replay, and operate.
import kitaru
@kitaru.flow
def research_flow(topic: str) -> str:
result = durable_agent.run_sync(f"Research {topic}")
return result.output
The important thing is what did not change.
The Pydantic AI agent is still a Pydantic AI agent. The model, tools, prompt, dependencies, and output behavior stay in the harness. Kitaru does not replace Pydantic AI. It gives the run a durable runtime underneath it.
In the default granular mode, the adapter can persist model requests, tool calls, and MCP calls as individual runtime boundaries. That changes the failure model.
Without runtime boundaries, a failure halfway through an agent turn usually means rerunning the whole turn. With granular checkpoints, a failed tool call does not have to erase the model calls and tool calls that already succeeded.
A typical run starts to look like this:
@flow research_flow(topic)
└── durable_agent.run_sync(prompt)
├── checkpoint: model_request_1
├── checkpoint: search_web_tool_1
├── checkpoint: model_request_2
├── checkpoint: read_page_tool_1
├── checkpoint: model_request_3
└── output
One practical caveat: granular checkpoints need room to create their own checkpoint boundaries. Do not wrap the whole durable_agent.run_sync(...) call inside another @kitaru.checkpoint if you want per-model-call and per-tool-call granularity. Put the agent run directly in the flow body, then add explicit checkpoints around other durable boundaries where they make sense.
Those calls and checkpoints are the runtime layer becoming visible. They change what happens when the run fails, pauses, or needs to be inspected later.
What changes when the run becomes durable
Imagine the agent has already searched several sources, investigated six links, and spent tokens building context. Then one URL fetch fails.
Without durable runtime state, you rerun the whole agent and hope it makes similar decisions on the way back to the failure. With Kitaru, completed checkpoints stay completed: the earlier model and tool calls are read from durable checkpoint state, the failed boundary runs again, and the execution continues from there.
Without runtime:
fail at call 8 → rerun calls 1-8
With Kitaru:
fail at call 8 → reuse calls 1-7 → rerun call 8
For short single-call agents this barely matters. For agents that make ten, twenty, or fifty calls — and we’ve spoken with customers whose agents have been running for weeks — the more work an agent has done, the more expensive it is to forget.
Durability also changes how an agent waits. When a run needs a human to approve an answer or confirm an action, a local script reaches for input() or a polling loop. That falls apart the moment the run is remote, the human is offline, or you do not want to pay for idle compute. With the Pydantic AI adapter, a tool can become a human-in-the-loop wait:
from kitaru.adapters.pydantic_ai import hitl_tool
@hitl_tool(question="Approve publishing this brief?", schema=bool)
def approve_publish(summary: str) -> bool: ...
When the agent reaches this tool, the Kitaru execution pauses. A human, webhook, CLI command, dashboard, or MCP client can provide the input later, and the same execution resumes from the same logical point.
Durable runs also leave evidence behind. Kitaru stores prompts, tool calls, tool results, errors, and final answers as checkpoint artifacts, and you can promote the final output into a named artifact so a reader can jump straight to it. That is a different job from tracing. If you use Pydantic AI, Pydantic Logfire is still where you look for span-level visibility into model calls, latencies, and token usage. Logfire shows the trace; Kitaru keeps the replayable execution you can operate on afterwards.
That word matters: operate. Once a run is durable, it becomes an object that humans inspect in the UI, developers drive from the CLI, services hit through the API, and other agents query through MCP. You can ask a coding assistant:
“Look at the failed News Scout run and tell me which tool call broke.”
Through Kitaru’s MCP server, the assistant can query the execution, inspect checkpoint metadata, read artifacts, and fetch logs — no pasted traceback required. That is where durable execution becomes agent-native.
Why a new runtime, when Temporal and DBOS exist?
Kitaru is not the only durable runtime for a Python agent. Pydantic AI already supports Temporal, DBOS, Prefect and Restate as durable-execution integrations. Inngest is also a serious option for TypeScript-first agent products. Each of those is the right answer to a slightly different problem.
Temporal makes the most sense when the hard problem is long-lived, cross-service orchestration with a mature control plane: signals, queries, updates, retries, durable timers, and a UI for your workflows. The price you pay is the workflow/activity split: agent code has to be deterministic at the top, with every model call and tool call pushed into an activity. DBOS is excellent when Postgres is already the center of the application. It checkpoints workflows into your existing database, so there is no separate orchestration server to deploy, and in the right case workflow state and application state can share a single transaction. Restate is a strong choice for event-sourced services with durable RPC-like calls and idempotent invocation. Inngest fits when the rest of the stack is serverless TypeScript and the work is event-driven step functions with first-class realtime publishing. If your problem already matches one of those shapes, use them.
We made a different bet in three specific ways. First, the durable boundary in Kitaru is the agent action itself (a model call, a tool call, a wait for a human, an artifact save), expressed as a plain Python primitive (@flow, @checkpoint, wait, save) rather than a deterministic workflow body with side effects pushed elsewhere. That granularity matches how AI agents actually fail: not in control flow, but in expensive or flaky external calls. Second, the same flow body can run in any of the execution targets we listed earlier (inline process, isolated container, Kubernetes job, cloud job, external tool) without rewriting the agent. The agent code doesn’t have to know where it runs. Third, Kitaru is sync-first; you write ordinary Python, not a DSL.
Kitaru is the runtime we wanted when the agent run is the center of gravity (checkpoints, artifacts, memory, human waits, replay), and when the same code has to run on a laptop and in production without rewrites.
What News Scout taught us about runtime-shaped agents
To make the runtime boundary concrete, we built News Scout: a Pydantic AI agent that searches news sources, investigates articles, scores what matters, and writes a short briefing.
News Scout was useful because it was not one prompt and one answer. It behaved like production agents usually behave: it searched, read, made choices, called external tools, spent real tokens, and produced an output a human might want to keep.
That made three runtime lessons obvious.
Replay is most valuable around unstable boundaries
News Scout uses tools for searching news, searching live social sources, investigating URLs, and fetching raw pages. The specific tools matter less than their shape: they are external, sometimes slow, sometimes flaky, and often expensive to repeat.
The core shape is still just a Pydantic AI agent with a Kitaru runtime wrapper:
from pydantic_ai import Agent
from kitaru.adapters.pydantic_ai import CapturePolicy, KitaruAgent
scout_agent = KitaruAgent(
Agent(
"anthropic:claude-sonnet-4-6",
name="news_scout",
tools=[search_news, search_twitter, investigate, fetch_url],
system_prompt=SYSTEM_PROMPT,
),
granular_checkpoints=True,
capture=CapturePolicy(tool_capture="full"),
)
At runtime, those model calls and tool calls become checkpoints:
@flow news_scout(interests)
├── scout_agent.run_sync(prompt)
│ ├── checkpoint: model_request_1
│ ├── checkpoint: search_news_tool
│ ├── checkpoint: model_request_2
│ ├── checkpoint: investigate_tool
│ ├── checkpoint: model_request_3
│ └── ...
└── checkpoint: publish_report
└── artifact: final_report
If a page times out halfway through the investigation, we do not want to ask the model to rebuild the whole chain of reasoning from scratch. We want to keep the model calls and tool calls that already worked, retry the failed boundary, and continue.
Without durable runtime state:
fail at fetch 8 → rerun model calls and fetches 1-8
With Kitaru:
fail at fetch 8 → reuse completed checkpoints → rerun fetch 8
That is the operational difference between “the agent failed” and “one unstable boundary failed, and the run still knows how to continue.”
This is where Kitaru’s replay model becomes useful for correction, not just retry. If an investigation step produced the wrong summary, you can replay from that checkpoint, or override that checkpoint's output with a corrected value and let Kitaru rerun the downstream work. That makes replay less like “try the whole run again” and more like editing one saved state and continuing from there.
The final answer deserves its own artifact
A trace is great when debugging the path the agent took. But the person reading a news briefing usually does not want to reconstruct the answer from model spans and tool outputs. They want the report.
That is why News Scout promotes the briefing into a named final_report artifact.
The trace tells you how the agent got there. The artifact gives humans, services, and other agents a stable object to read afterwards.
Granularity is a design choice, not a badge of honor
More checkpoints make replay more precise, but they also make the execution tree busier. The goal is not to checkpoint everything just because you can. The goal is to put durable boundaries where resuming from that point would feel natural.
For News Scout, model calls and URL fetches are useful replay boundaries because they are expensive, flaky, or both. If a fetch fails, replaying only that fetch is helpful. If a model call has already spent tokens building useful context, keeping it is valuable.
For another agent, a larger phase might be the better boundary. A data-cleaning agent might checkpoint after each dataset stage. A customer-support agent might checkpoint after each approved action. The right boundary is the place where, after a crash, you would say: “Start again from here, not from the beginning.”
That is the interesting part of News Scout. It’s less of a Pydantic AI example and more a small production-shaped workload that shows what changes when an agent run becomes durable.
Where this fits
By this point in the post, the split should be clear: Pydantic AI is where you define the agent, while Kitaru becomes useful when the run itself needs to be kept around, resumed, inspected, or operated.
For a short-lived local helper, a harness is often enough; if the run fails, you start it again and nothing important is lost. The runtime layer starts to matter when starting over is no longer harmless: maybe the agent has already paid for several model calls, gathered useful context, touched flaky external services, paused for a human, or produced artifacts that other people and systems need to read later.
Kitaru by ZenML is built for that point in the lifecycle. You still write normal Pydantic AI code, but the run gets durable state underneath it: checkpoints, replay, resume, wait states, artifacts, logs, execution history, and operational control. That gives the agent somewhere to land when production does ordinary production things: a URL times out, a process dies, a human approval arrives later than expected, or someone needs to understand a failed run without reconstructing it from pasted tracebacks.
It is especially useful when a team wants that production behavior to work across more than one agent harness. The durable execution story can live underneath the app code instead of being rebuilt separately for every framework.
So the practical question is not whether every agent needs a separate runtime. Many do not. The question is what happens when the run disappears. If the answer is “nothing much,” the harness may be enough. If the answer is wasted token spend, lost intermediate work, a stuck approval, or an opaque debugging session, then the runtime layer is doing real work.
Try it yourself
Clone the repo to have access to the example projects:
git clone https://github.com/zenml-io/kitaru
cd kitaru
Install the local, Pydantic AI, and LLM extras:
uv sync --extra local --extra pydantic-ai --extra llm
Initialize Kitaru and log in to the local dashboard:
kitaru init
kitaru login
Run News Scout:
cd examples/end_to_end/news_scout
uv run scout.py --interests "ai agents, robotics"
Then break it on purpose.
Kill the process mid-run. Replay from a failed or interrupted checkpoint. Open the dashboard. Inspect the tool artifacts. Open the final_report. Better yet, connect to our MCP server and use your own agents to inspect the artifacts generated.
If you want to try the same runtime shape yourself, start with the full News Scout example: run it, break it on purpose, replay it, and inspect the artifacts it leaves behind. If this is the kind of runtime layer you want underneath your own agents, give Kitaru by ZenML a star on GitHub and follow along as we keep building.
