Qualio provides a compliance and quality management platform to medical device makers, pharma companies, and biotechs. Customers in those industries face audits where a regulator can demand evidence that the software they use behaves the way the vendor said it would. This means every Qualio release has to ship with that evidence attached, and customers have to verify each release on their own systems before they can use it in their regulated workflows.
The challenge: Shipping AI to customers who have to certify every release
For over a decade, Qualio has cleared that bar with browser-automation tests and release videos: a button works, a form submits, and the video proves it. The system is legible to auditors and scales because the answers are binary.
AI broke the model. A browser test can confirm an assistant rendered, but it cannot confirm the assistant found the right policy document, cited it accurately, or refused to invent a regulation. Without a way to put that kind of behavior in a regression suite, every model upgrade or prompt change risked silently degrading the product, and Qualio could not put a release in front of customers without the evidence those customers were contractually owed.
The team needed two things: an evaluation framework that produced auditable results, and an agent framework lightweight enough to iterate on without dragging the rest of the engineering org through deployments for every tool change.
Why Pydantic AI won the framework evaluation
When looking at frameworks, product architect Níall Ó Beaglaoich ran head-to-head assessments of Bedrock Agents, AG2 (formerly AutoGen), Strands Agents, LangGraph, and Pydantic AI. Bedrock had the home-field advantage: Qualio's customer contracts require data and compute to stay inside AWS. Defining an agent in Bedrock, though, meant defining it as a CDK construct, which meant an infrastructure deployment for every tool tweak. Iteration speed suffered.
Pydantic AI won on iteration speed. As Níall puts it:
Pydantic AI won because of its good abstractions for defining an agent, encapsulating it very simply, and just tying it to tools that were simple Python methods.
Human-in-the-loop without fighting the framework
Iteration speed is not the only thing that sets Pydantic AI apart. Qualio's compliance workflows need a human in the loop: for certain actions, the agent has to stop and get a person to confirm or reject before it proceeds. In contrast to AG2 and Strands, Pydantic AI made it easy to implement. They added a simple snippet to the relevant tool invocations that sends a prompt to the user over the websocket connection and waits on their confirmation or rejection.
From many agents to one
Qualio's assistant started as a multi-agent system: one agent per domain (documents, events, compliance, and so on) and a main agent that delegated to them. As the team got further into the build, the message-history coordination between sub-agents began to crowd out the business logic and added latency with every handoff, so they consolidated to one agent using two high-level tools instead of ten.
The migration happened overnight. The team feature-flagged the old setup against the new, and ran them in parallel until the consolidated version was clearly the better one. Pydantic Evals carried the team across the rewrite with confidence by surfacing regressions as they happened, enabling the team to verify that the new architecture still handled every scenario the old one did. By picking Pydantic AI, Qualio chose a framework light enough to rewrite as their architecture evolved to serve real users.
Evals that gate deploys, not dashboards
Picking the right framework was only half the problem. The other half was knowing whether the AI Qualio built was actually behaving the way their customers needed it to. Evals are regression tests for LLM behavior: did the model find the right document, cite it accurately, stay on topic, refuse to invent a regulation. Qualio wires its evals directly into the deploy pipeline. Across its AI features, the team maintains roughly 160 test cases and 300 evaluations, all running against every prompt change, orchestration change, or model change. A pass rate below their threshold blocks the release.
Pydantic Evals is used across Qualio's AI-based features to keep them honest. The first project is compliance intelligence, which reads a customer's quality management content across modules and flags gaps against the standards they need to certify against. The second is the new chat-based assistant built on Pydantic AI.
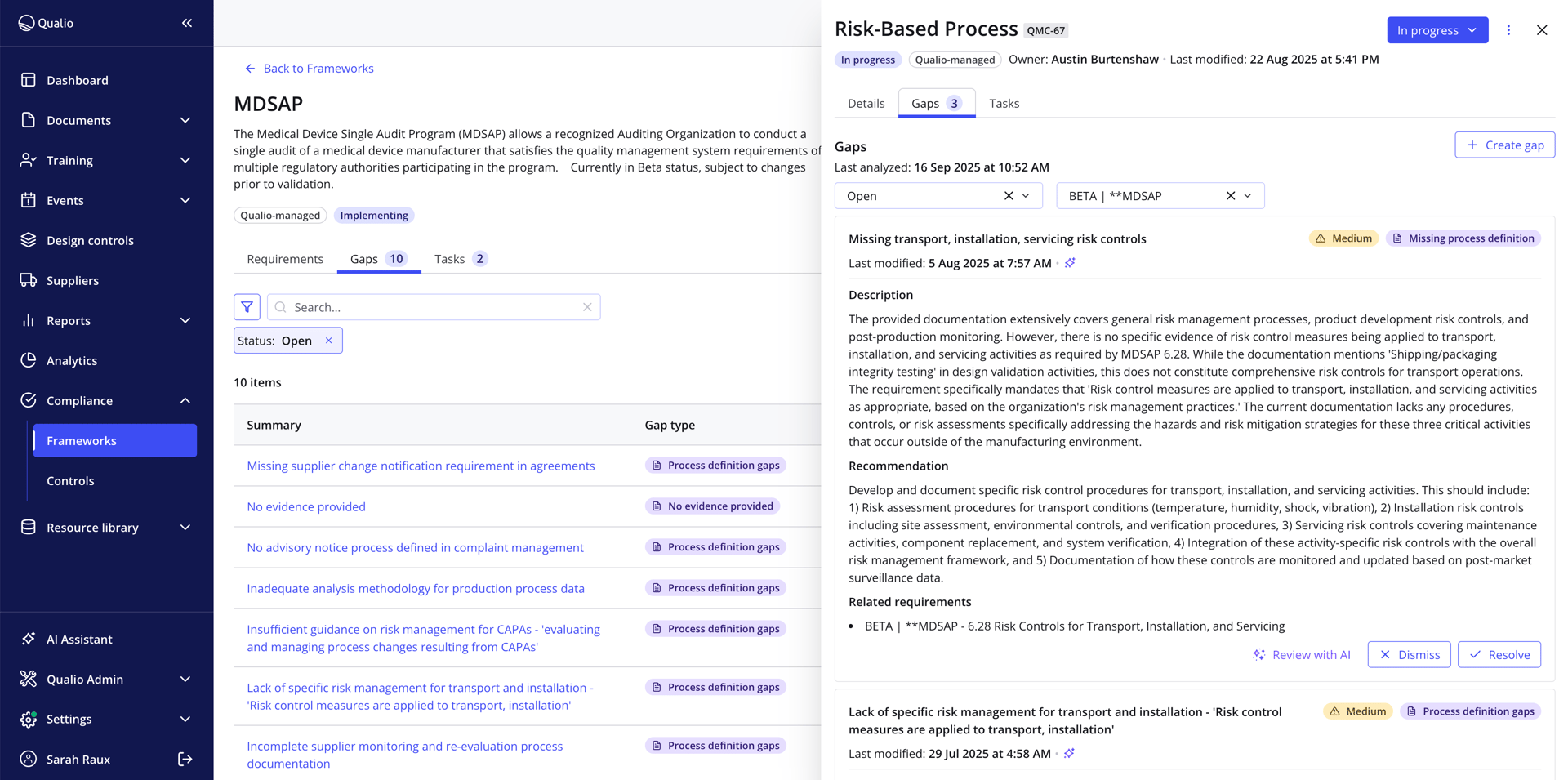
Most of those evaluators use a cheaper LLM as a judge, scoring the production model's output against criteria the team writes in plain language. One evaluator hooks into spans to confirm the agent called the tools it was supposed to. With plain language, non-technical reviewers can read the criteria and approve them, which is how the same evidence ends up in front of customers' compliance teams during due-diligence reviews. The eval suite lets Qualio ship AI to customers who certify every release, with proof already in hand.
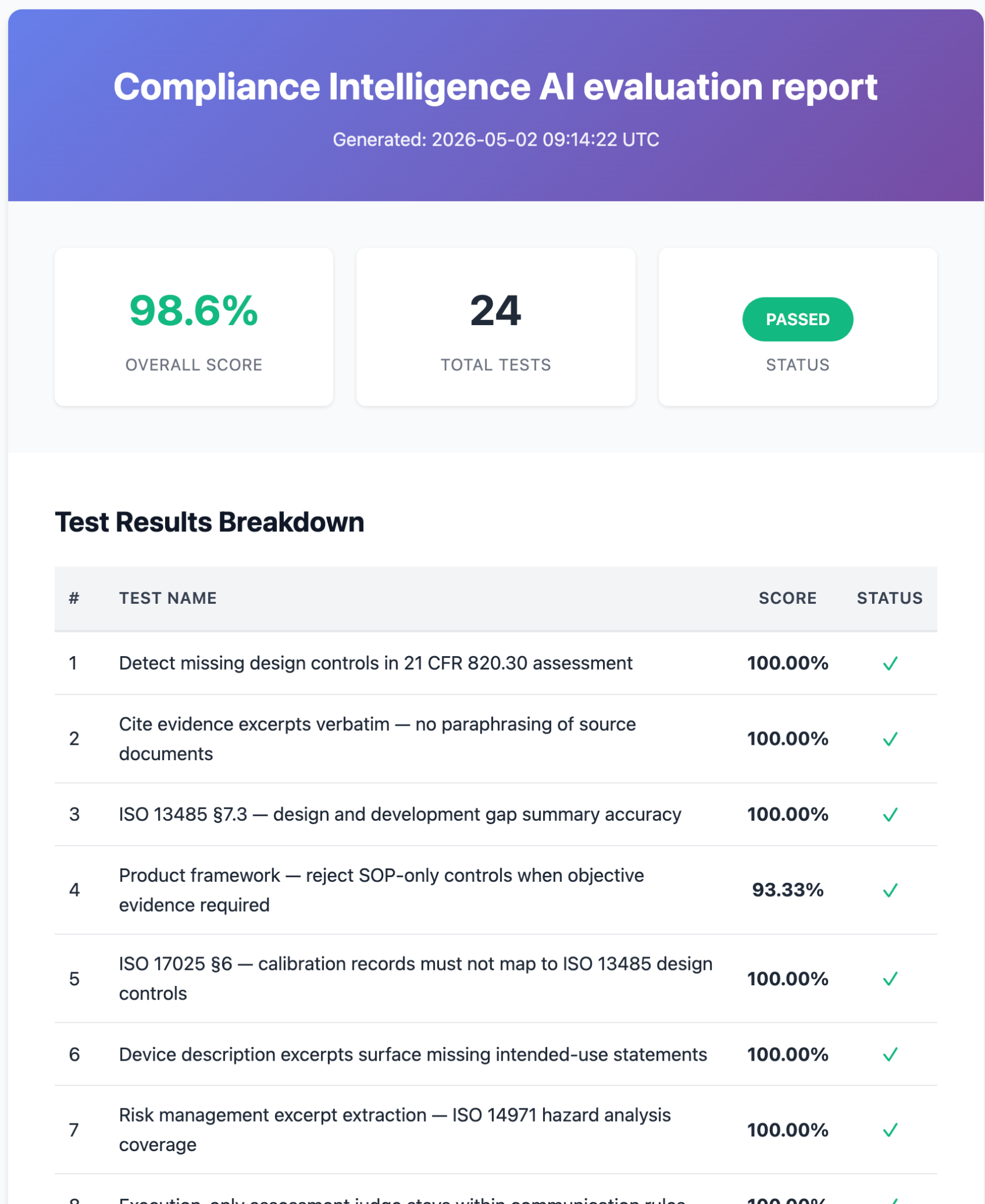
The results
A year in, Qualio runs both AI products on the Pydantic stack and gates every release through the same eval suite. The team continues shipping with confidence in the framework they chose, and the question they get asked most often, "how do you prove this works?", has a real answer they can hand to regulators.
There's no point that has come where we'd say we're betting on the wrong horse. The decision a year ago was just the right one.
— Joshua Görner, Engineering Manager at Qualio
Key takeaways
- Start with a single agent and add complexity when you need it. Qualio's assistant covers more ground with one agent and a small set of high-level tools than it did as a multi-agent system. The team got there by evolving the architecture as they learned what their users needed, not by getting it right the first time.
- Wire evals to enforce quality. Qualio gates deploys on a pass-rate threshold. Other teams sample production traffic with online evals. The same evaluator code runs in both setups: evals deliver value when they are attached to a decision, whether that decision is a merge gate or a live alert.
- Pick a framework you can change your mind in. Architectural assumptions about agents tend to evolve with real usage, so frameworks light enough to rewrite as your architecture changes are ones to invest in. Qualio rebuilt their tool surface overnight because Pydantic AI did not have an opinion about how the agent should be wired.
Want to build agents you can prove behave? Get started with Pydantic.
Frequently asked questions
What is Pydantic AI?
Pydantic AI is an open-source agent framework built by the team behind Pydantic, the Python validation library. Tools are plain Python functions, abstractions stay thin, and the framework doesn't enforce a specific orchestration pattern. Qualio chose Pydantic AI over Bedrock Agents, AG2, LangGraph, and Strands Agents for those qualities, citing iteration speed as the deciding factor.
How does Pydantic AI compare to LangGraph, AG2, Bedrock Agents, and Strands Agents?
In Qualio's head-to-head evaluation in mid-2025, Pydantic AI won on iteration speed and framework simplicity. Bedrock Agents required defining each agent as a CDK construct, forcing a deployment for every tool change. AG2, LangGraph, and Strands Agents were heavier than the team needed for two production AI workloads. Pydantic AI's plain-Python-function tools and unopinionated orchestration let Qualio rewrite their assistant architecture from multi-agent to single-agent overnight, without fighting the framework.
What is Pydantic Evals?
Pydantic Evals is an open-source Python library for testing LLM behavior. It runs evaluators against an agent or model's output, scoring against criteria the team defines, and supports both CI-style deploy gating and live online evaluation against production traffic. Qualio uses Pydantic Evals to gate every release behind their set pass-rate threshold across roughly 160 test cases and 300 evaluations.
What are LLM evals, and why do AI teams need them?
Evals are regression and quality tests for LLM behavior: did the model find the right document, cite it accurately, stay on topic, refuse to invent information. Teams shipping AI to production wire evals into the deploy pipeline so a behavior regression blocks the release, the same way a unit test failure does for code.
How do you use LLM-as-judge for evaluating AI agents?
LLM-as-judge evaluators use a cheaper model to score the production model's output against criteria written in plain language. Qualio's eval suite is almost entirely LLM-as-judge: the team writes criteria like "did the agent find the right policy" or "did the response stay within communication rules," and the judge model scores each test case against them. Plain-language criteria are also readable to non-technical reviewers, which means the same evaluations can become customer-facing evidence during compliance reviews.
Can Pydantic Evals run in production, not just CI?
Yes. The same evaluator code that runs in CI can be attached to live production traffic with Pydantic Evals' online evaluation API. Teams can sample production calls at a configurable rate, route results to OTel-compatible backends or custom sinks, and reuse the same evaluator definitions across CI and runtime. This makes evals useful both as merge gates and as live monitoring for behavior drift.
Why do AI teams move from multi-agent to single-agent architectures?
Multi-agent architectures distribute work across specialized sub-agents, but each agent carries its own message history, and coordinating those histories often crowds out the business logic. Qualio's assistant started with one agent per domain and a main agent that delegated to them. As the team built further, the coordination overhead grew faster than the value, so they consolidated to one agent with two high-level tools instead of ten. The migration happened overnight because Pydantic AI didn't constrain how the architecture should be wired.
