Update: If you find this article interesting, you might also like the TechCrunch article and Sequoia blog post about Pydantic.
I've decided to start a company based on the principles that I believe have led to Pydantic's success.
I have closed a seed investment round led by Sequoia, with participation from Partech, Irregular Expressions and some amazing angel investors including Bryan Helmig (co-founder and CTO of Zapier), Tristan Handy (founder and CEO of Dbt Labs) and David Cramer (co-founder and CTO of Sentry).
Why?
I've watched with fascination as Pydantic has grown to become the most widely used Python data validation library, with over 40m downloads a month.
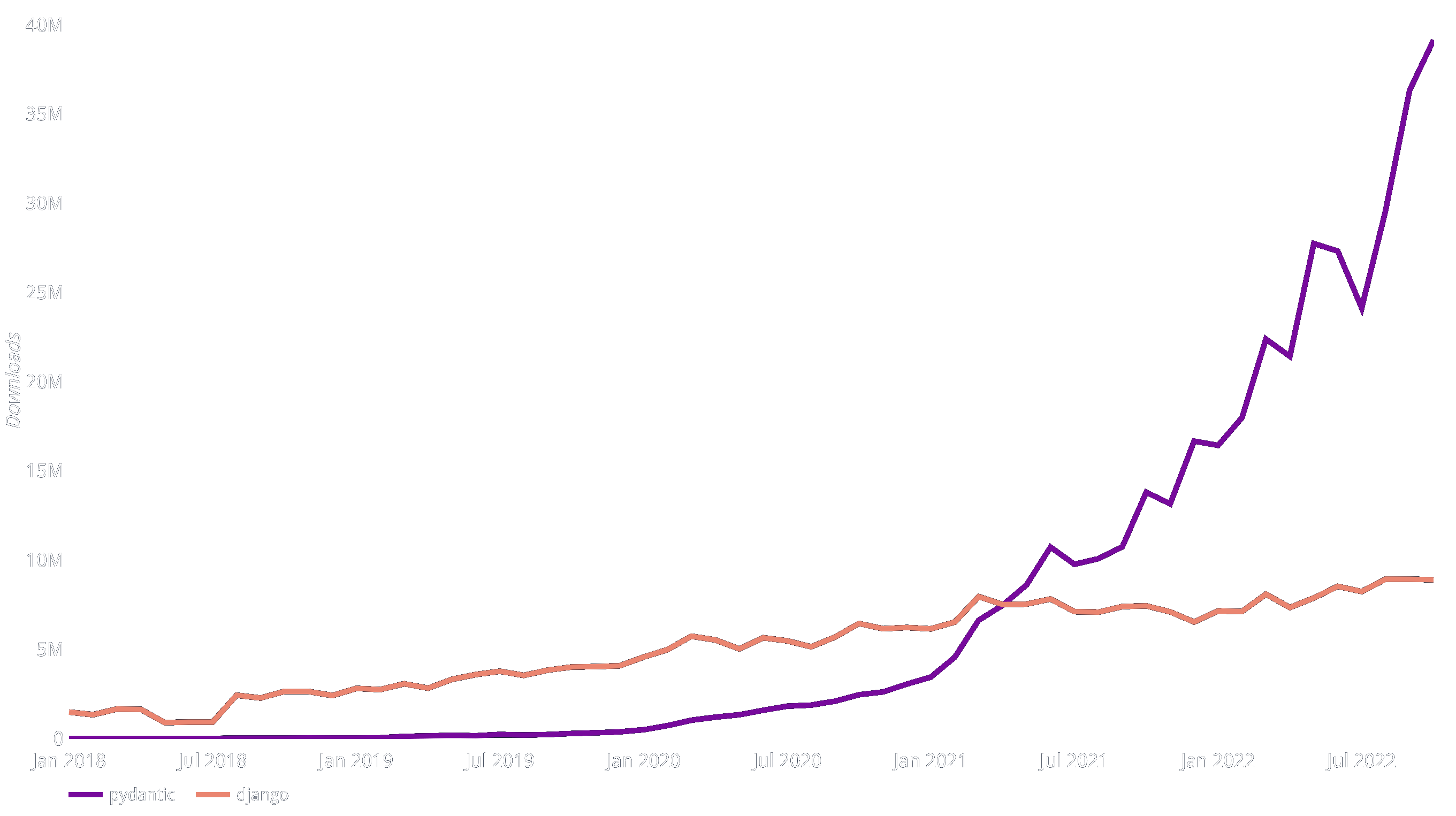
By my rough estimate, Pydantic is used by 12% of professional web developers! †
But Pydantic wasn't the first (or last) such library. Why has it been so successful?
I believe it comes down to two things:
- We've always made developer experience the first priority.
- We've leveraged technologies which developers already understand — most notably, Python type annotations.
In short, we've made Pydantic easy to get started with, and easy to do powerful things with.
I believe the time is right to apply those principles to other, bigger challenges.
"The Cloud" is still relatively new (think about what cars or tractors looked like 15 years after their conception), and while it has already transformed our lives, it has massive shortcomings. I think we're uniquely positioned to address some of these shortcomings.
We'll start by transforming the way those 12% of web developers who already know and trust Pydantic use cloud services to build and deploy web applications. Then, we'll move on to help the other 88%!
Cloud services suck (at least for us developers)
Picture the driving position of a 1950s tractor — steel seat, no cab, knobs sticking out of the engine compartment near the component they control, hot surfaces just waiting for you to lean on them. Conceptually, this isn't surprising — the tractor was a tool to speed up farming; its driver was an afterthought, and as long as they could manage to operate it there was no value in making the experience pleasant or comfortable.

Today's cloud services have the look and feel of that tractor. They're conceived by infrastructure people who care about efficient computation, fast networking, and cheap storage. The comfort and convenience of the developers who need to drive these services to build end-user facing applications has been an afterthought.
Both the tractor and the cloud service of the past made sense: The majority of people who made the purchasing decisions didn't operate them, and those who did had little influence. Why bother making them nice to operate?
"At least it's not a
cart horseWindows box in the corner — quit complaining!"
Just as the experience of driving tractors transformed as their drivers' pay and influence increased, so cloud services are going through a transformation as their operators' pay and influence increases significantly.
There are many examples now of services and tools that are winning against incumbents because of great developer experience:
- Stripe is winning in payments despite massive ecosystem of incumbents
- Sentry is winning in application monitoring, even though you can send, store, and view the same data in CloudWatch et al. more cheaply
- Vercel is winning in application hosting by focusing on one framework — Next.js
- Python is winning against other programming languages, even though it's not backed by a massive corporation
- Pydantic is winning in data validation for Python, even though it's far from the first such library
In each case the developer experience is markedly better than what came before, and developers have driven adoption.
There is a massive opportunity to create cloud services with great developer experience at their heart. I think we're well positioned to be part of it.
Developers are still drowning under the weight of duplication
The story of the cloud has been about reducing duplication, abstracting away infrastructure and boilerplate: co-location facilities with servers, cages and wires gave way to VMs. VMs gave way to PaaS offerings where you just provide your application code. Serverless is challenging PaaS by offering to remove scaling worries.
At each step, cloud providers took work off engineers which was common to many customers.
But this hasn't gone far enough. Think about the last web application you worked on — how many of the views or components were unique to your app?
Sure, you fitted them together in a unique way, but many (20%, 50%, maybe even 80%?) will exist hundreds or thousands of times in other code bases. Couldn't many of those components, views, and utilities be shared with other apps without affecting the value of your application? Again, reducing duplication, and reducing the time and cost of building an application.
At the same time, serverless, despite being the trendiest way to deploy applications for the last few years, has made much of this worse — complete web frameworks have often been switched out for bare-bones entry points which lack even the most basic functionality of a web framework like routing, error handling, or database integration.
What if we could build a platform with the best of all worlds? Taking the final step in reducing the boilerplate and busy-work of building web applications — allowing developers to write nothing more than the core logic which makes their application unique and valuable?
And all with a developer experience to die for.
What, specifically, are we building?
I'm not sharing details yet 😃.
The immediate plan is to hire the brightest developers I can find and work with them to refine our vision and exactly what we're building while we finish and release Pydantic V2.
While I have some blueprints in my head of the libraries and services we want to build, we have a lot of options for exactly where to go; we won't constrain what we can design by making any commitments now.
If you're interested in what we're doing, hit subscribe on this GitHub issue. We'll comment there when we have more concrete information.
The plan
The plan, in short, is this:
- Hire the best developers from around the world (see "We're Hiring" below)
- Finish and release Pydantic V2, and continue to maintain, support and develop Pydantic over the years
- Build cloud services and developer tools that developers love
Pydantic, the open source project, will be a cornerstone of the company. It'll be a key technical component in what we're building and an important asset to help convince developers that the commercial tools and services we build will be worth adopting. It will remain open source and MIT licenced, and support and development will accelerate.
I'm currently working full time on Pydantic V2 (learn more from the previous blog post). It should be released later this year, hopefully in Q1. V2 is a massive advance for Pydantic — the core has been re-written in Rust, making Pydantic V2 around 17x faster than V1. But there are lots of other goodies: strict mode, composable validators, validation context, and more. I can't wait to get Pydantic V2 released and see how the community uses it.
We'll keep working closely with other open source libraries that use and depend on Pydantic as we have up to this point, making sure the whole Pydantic ecosystem continues to thrive.
On a side note: Now that I'm paid to work on Pydantic, I'll be sharing all future open source sponsorship among other open source projects we rely on.
We are were hiring
We've had an extraordinary response to this announcement, and have hired an extremely talented team of developers. We therefore aren't actively hiring at this time. Please follow us on Twitter/LinkedIn/Mastodon to hear about future opportunities.
If you're a senior Python or full stack developer and think the ideas above are exciting, we'd love to hear from you.
Please email careers@pydantic.dev with a brief summary of your skills and experience,
including links to your GitHub profile and your CV.
Appendix
"12% of professional web developers" claim
At first glance this seems like a fairly incredible number, where does it come from?
According to the StackOverflow developer survey 2022, FastAPI is used by 6.01% of professional developers.
According to my survey of Pydantic users, Pydantic's usage is split roughly into:
- 25% FastAPI
- 25% other web development
- 50% everything else
That matches the numbers from PyPI downloads, which shows that (as of 2023-01-31) Pydantic has 46m downloads in the last 30 days, while FastAPI has 10.7m — roughly 25%.
Based on these numbers, I estimate Pydantic is used for web development by about twice the number who use it through FastAPI — roughly 12%.
