
It's been a busy few months! I'm back from the latest of three conferences: PyData London in June, where I presented The Human-in-the-Loop is Tired. Before that it was PyCon DE & PyData in Darmstadt in April, PyCon Italia in Bologna in May.
The conversations I had between sessions this year had a particular texture. There's a general hum of people working through something. I want to try and put some of it into words, partly because it deserves documenting, and partly because you might find it useful to know you're not the only one feeling it.
But first, some data analysis
What kind of PyCon attendee would I be if we didn't kick off with some data analysis?
I normalised 675 talk abstracts across PyCon DE & PyData, PyCon Italia, and PyData London (345 from 2025, 330 from 2026) and counted how often each theme appeared in title and abstract.
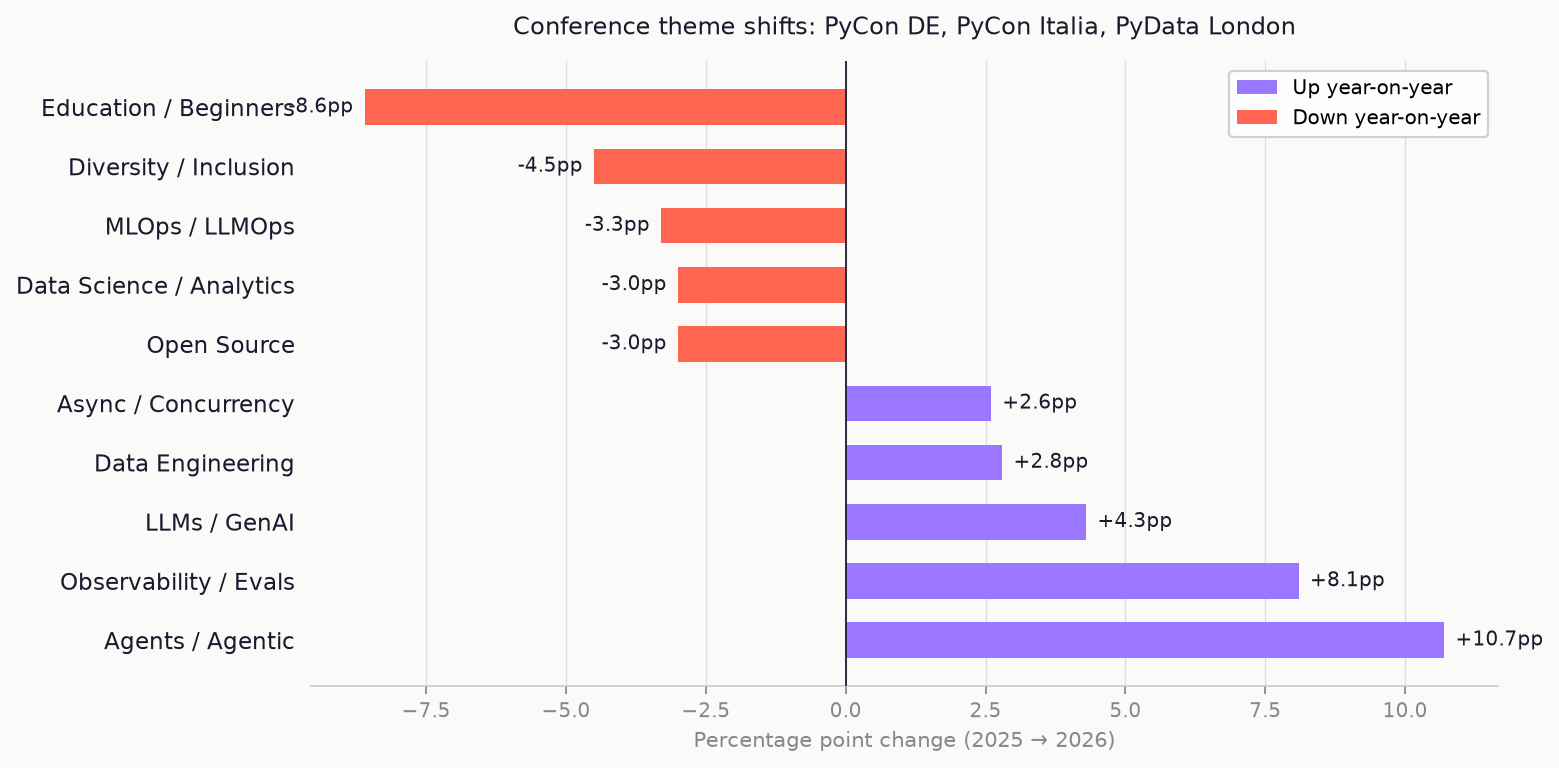
The agent shift is the most legible signal in the data. Sessions covering agents and agentic patterns went from 8% of the programme to 19% - roughly one in five slots - and it moved the same direction at all three events. Most topics are uneven; one community picks something up while another drops it. Agents are not like that right now. They're genuinely everywhere.
The flip side is equally legible: beginner and education content dropped from 23% to 15%. It's hard not to read that alongside everything else happening right now — junior roles contracting, everyone scrambling to stay relevant, the question hanging over every learning decision: will this still matter in two years?
Observability and evals are up too. This is not something I'm neutral about. It's close to what we're building with Logfire, and I think the rise is real: as agents have become more common, the questions about how to see what they're doing have become harder to avoid.
The aggregate numbers flatten real differences. Break it down by conference and the picture is messier, which is more interesting:
| Theme | 2025 → 2026 | PyCon DE | PyCon Italia | PyData London |
|---|---|---|---|---|
| Agents / Agentic | 8% → 19% | +12 | +7 | +14 |
| Education / Beginners | 23% → 15% | −6 | −5 | −21 |
| Observability / Evals | 11% → 19% | +9 | 0 | +22 |
| Diversity / Inclusion | 14% → 9% | −3 | −10 | +5 |
| LLMs / GenAI | 22% → 27% | −1 | +7 | +13 |
| MLOps / LLMOps | 7% → 3% | −3 | 0 | −9 |
| Data Science / Analytics | 20% → 17% | −1 | −5 | −5 |
| Open Source | 21% → 18% | −9 | +6 | −6 |
| Data Engineering | 8% → 10% | +3 | +2 | +6 |
| Async / Concurrency | 5% → 7% | +5 | +2 | −1 |
Numbers show percentage point change in share of sessions. Bold = more than 5 points from the overall trend. Worth noting that programmes reflect what the community submits, not organiser decisions.
Open Source went in opposite directions in Darmstadt versus Bologna in the same year. I don't have a clean explanation for that.
Also, worth noting some topics missing, not-at-random:
- Job displacement and economic impact
- AI in education
- Green and sustainable AI
These are not obscure concerns - call it sparse attention to the externalities, if you like. They just aren't what's getting submitted or programmed right now.
And on to the vibes
Never ask a barber if you need a haircut
The loudest agent influencers: "Set up loops, add more self-correction, trust the pipeline to check itself". Maybe even "Don't read the code". I get the appeal of the vision! I'm actively working on my own "agent ops" (although I still read all the code). At the same time, a lot of this advice is coming from people who have a material interest in you burning more tokens.
You should never ask a barber if you need a haircut. And you should never ask a model provider whether you need more AI agents. ^-^
So yes these are possible answers to the challenges of agentic engineering:
- If the agent is producing bad output, make it loop more
- If the system prompt isn't working, make it longer
But this feels to me like "just test more" as an answer to a specification problem. You're addressing a symptom. More iterations of an underspecified process doesn't produce a better-specified result, it produces more output of uncertain quality.
In Samuel Colvin's PyData London keynote, on sandboxed code execution, Pydantic Monty, and keeping wild LLMs tame, there was a moment where he described asking an agent very nicely to please do the thing you're asking it to do. He meant it as an observation about system prompts: they're suggestions, not instructions. You can get more specific, more dogmatic, more precise in how you phrase them. At some point the model will forget what was at the top by the time it reaches the bottom, or it'll decide it knows better, or it'll do something in the general vicinity of what you asked in a way that passes the vibes check but misses the point entirely. These are known failure modes. More prompting doesn't fix them.
In the same vein: I remember reading a paper for my AI Ethics reading group years ago - their pitch: model-free hyperparameter tuning, with a view to picking the config space which performs best against your chosen fairness metrics. The kicker: most of the authors were from Amazon. Burning more compute is not the same as making better decisions faster. These are separate questions that are currently being conflated.

Are plans just waterfall making a sneaky comeback?
Earlier this year I invested heavily in detailed upfront plans. Genuinely invested: writing them, having agents revise them, reading what came back and revising again. I was taking this seriously as a workflow. And I found that the longer the plan, the less likely I was to follow it end-to-end.
What kept happening: the plan would run until the first real decision branch appeared, and then we'd diverge. The remaining two-thirds of the plan became irrelevant, because we'd taken a fork the plan hadn't anticipated and hadn't been able to anticipate.
This has a smell. It's waterfall. Plan too far ahead and you can't account for the decisions that only become visible once you're doing the work. The way you know what you're building is by building it - by hitting the frictions, seeing the decision points that were vague at the start become explicit, being forced to grapple with them in the moment. That's not a failure of the planning process; it's what planning is like when the problem has real complexity, and no 'right' answer.
It's only recently that I brought this together - that the fantasy of "drop one prompt at the top of the Rube Goldberg machine and out comes perfect output at the bottom" has the same obvious failure modes as the big requirements docs we wrote under waterfall.
My most productive working pattern right now is high-contact: short loops, frequent feedback, staying close to what the agent is doing. Staying in it. Not because I need to micromanage, but because you only understand what you're building by building it. The more removed you are from the thing you are building, the harder it is to develop that sense memory, those instincts. There's a hand-body-mind connection that enables a form of learning that passive skimming simply does not, and you can't shortcut it.
"Any theory of human intelligence which ignores the interdependence of hand and brain function is grossly misleading and sterile." — Frank R. Wilson, The Hand, 1998
The unresolved tension: when do you even use inference?
Engineers are trained on systems that behave predictably. You write a test, it passes or fails. You add a function, you can reason about what it does. Agents don't work like that, and a lot of the friction I kept hearing about in hallway conversations is really just that dissonance, showing up in different forms.
The question underneath most of these conversations is: how do you get the juice from the magic prediction box without going off the rails? Too much determinism and you're back to fragile cron jobs. Too much inference and you're in hallucination city. The interesting engineering problem is figuring out where to draw the line - or design that loop. Which decisions actually benefit from stochastic reasoning? And which ones just need a function that returns a value?
I liked the framing I heard from Jeremiah Lowin's PyData London keynote: the skill isn't avoiding non-determinism, it's learning to reason about system behaviour even when the components aren't deterministic. That's not something most engineers have had to develop. It's not a tooling gap - it's a mental model gap.
PyCon DE & PyData: "Software engineering matters more, not less, in the age of agentic AI."
Plus, new engineering challenges
Code mode - using code rather than inference to select and run tools - is interesting precisely because it's so immediately appealing to engineers, and then turns out to open a new can of worms. Where does the code run? What happens with multi-provider setups? Do you need a sandbox? Samuel Colvin's Monty work is a specific, serious engineering attempt to answer the sandbox question; Marcelo Trylesinski's talk at PyCon Italia on the MCP Python SDK is in the same spirit - better typing, refined API, actual testing primitives. The problem isn't resolved, but people are working on it with real engineering rigour rather than hoping the model figures it out.
Evals and observability have a similar challenge: understood in principle, complicated in practice. What I found in sessions is that most teams are still very early, we are unironically doing error analysis in spreadsheets, running manual spot checks. Nowhere near continuous evaluation against production data. Which makes sense: the concepts are new, the tooling hasn't consolidated yet, the muscle memory takes time.
The second-order questions are the ones I've been sitting with after conversations with our CTO, David Montague. How do you keep a gold dataset current as your system evolves? What happens when your trace retention window is shorter than the patterns you're trying to catch? How do you detect data drift in production before users find it for you rather than after? People are still figuring out how to run one eval, let alone maintain the infrastructure around them at scale.
RAG went through a similar arc and has come out the other side. The mention count at PyCon DE roughly halved — not because it went away, but because it graduated. The questions moved from "what is this?" to "we have it running, now how do we not embarrass ourselves." 2025 was the year of RAG, 2026 is agents. The hard questions didn't get answered, they moved. Graph-based orchestration is in that same early territory right now - proponents on both sides, no gold standard, and libraries that may look quite different in another year.
A note on sovereignty
Digital sovereignty was everywhere at both European conferences this year. Aaron Glenn's talk on cloud sovereignty was a keynote at PyCon DE. Ethics, privacy, and regulation showed up in roughly a quarter of European conference sessions. This is the year EU AI Act enforcement started to bite, and it's coinciding with a moment where AI companies themselves are having very public debates about their own direction. Non-American companies are, reasonably given the Fable drama, asking where their inference runs, who owns the weights, and what it means to be dependent on infrastructure they don't control. "Sovereign AI" is not a niche concern anymore. It's landed.

It's okay to be tired. It's okay to be cynical, and that doesn't make you a luddite.
This is the thing I kept saying in conference corridors across all three events, and the topic of my talk at PyData London.
For the first time in my experience of tech, I'm hearing from senior engineers - people with years of practice, people who've seen hype cycles before - that they feel the need to be seen as on the train. To publicly perform enthusiasm for the current moment even when their private experience is more mixed. To not be the person who's resisting, or worse, not getting it.
PyData London: "Copy-pasting from a chatbot is not a career path."
This is anxiety dressed up as positioning. And it has a real cost, because it makes it harder to have honest conversations about what's actually working. It also compounds: when the people with the most earned scepticism are busy performing belief, the people with less experience have fewer anchors.
For the first time I'm hearing people describe learning new things as anxiety-inducing rather than energising. The combination of factors is pretty clear once you hear it: things are still in flux, there are no engineering gold standards, learning materials are increasingly of uncertain quality (vibe-coded tutorials are not the same as considered documentation), and underneath it all is the question that nobody quite wants to ask out loud: will I even need to know this in two years? On what time horizon do I invest? How do you future-proof yourself when the landscape hasn't settled?
That's a different kind of learning anxiety than anything I've seen in tech before. Not the productive discomfort of hard things. Something more like exhaustion.
The non-LLM work is still here, the programme isn't monoculture. Time series, Bayesian stats, causal reasoning, proper data engineering - all present across all three conferences, being done seriously by serious people. My husband Andy Kitchen's Interventional Generalisation talk at PyCon DE for example: Pearl-style causal reasoning, expected interventional value, thinking about the world in terms of independent actors and their effects.
Andy's talk draws a distinction worth carrying out of the room: epistemic uncertainty, the kind that comes from not yet having enough information, is in principle reducible. Aleatoric uncertainty, the noise baked into outcomes, is not. Knowing which kind you're dealing with changes what you should do next. Most people in the field are navigating both, about their own work, right now.
You don't have to have it all figured out. No one does. Some of the most useful conversations I had this year were with people who admitted exactly that, in a corridor, between sessions. My bet's on community. Good things happen when you get enough people in a room who are all willing to be uncertain out loud.
We're building Pydantic AI and Logfire - tools that are, among other things, directly trying to solve the observability and reliability problems described above. We have roles open - come build with us.
