On July 2025, a user reported an issue about Pydantic potentially using more memory than needed on model instances. The user referred to PEP 412 – Key-Sharing Dictionary, but I then found out that PEP 412 wasn't really the bottleneck.
In this blog post, we are going to see how the original issue was investigated and how we can leverage bitsets to greatly reduce the memory usage of Pydantic model instances.
Table of Contents
Introduction
dicts and PEP 412
Internally, Python dictionaries are stored as a hash table. When constructing a dictionary instance, each key->value pair is inserted in this table following a specific algorithm (long story short: the hash of the key is computed, and the value gets inserted depending on whether there is a match in the table with that hash). Such a hash table has 3 columns:
| Hash | Pointer to key | Pointer to value |
|---|---|---|
| 6558844463820098693 | -> 'a' | -> 1 |
| 8771437864645622406 | -> 'b' | -> 2 |
| -6104801815529482393 | -> 'c' | -> 3 |
(this table would be for the following dict: {'a': 1, 'b': 2, 'c': 3}).
In the majority of cases, instances of Python classes (including Pydantic models) store their attributes in a dictionary, under the __dict__ attribute:
class MyClass:
a: int
b: str
def __init__(self, a: int, b: str) -> None:
self.a = a
self.b = b
m = MyClass(1, 'test')
m.__dict__
#> {'a': 1, 'b': 'test'}
The issue is, for each instance of MyClass, you end up storing the same hashes and pointers to keys, and only the pointers to values are different. This is precisely what PEP 412 aims at solving.
The hash table is split into two: a "keys table", only stored once and tied to the MyClass type, and a "values table" for each instance, containing only the pointer to the attribute values.
This optimization can be seen in action. Profiling the following scripts:
dict_list = []
for _ in range(1_000_000):
dict_list.append({
'a': 1,
'b': '2',
'c': 1,
'd': 1,
'e': 2,
'f': 1,
'g': 1,
})
Memray results (memray run -o out.bin script.py && memray flamegraph out.bin -o out.html):
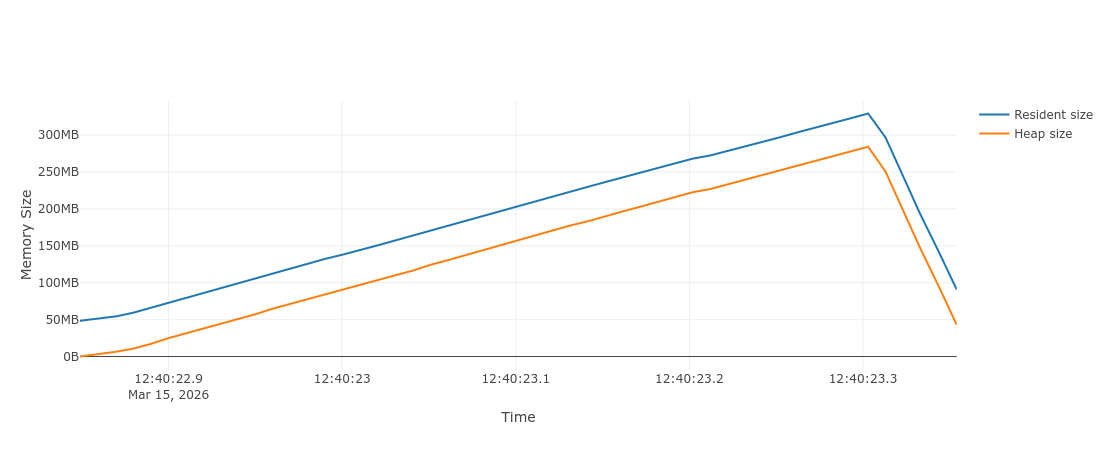
class A: ...
a_list = []
for _ in range(1_000_000):
a = A()
a.a = 1
a.b = '2'
a.c = 1
a.d = 1
a.e = 2
a.f = 1
a.g = 1
a_list.append(a)
Memray results (memray run -o out.bin script.py && memray flamegraph out.bin -o out.html):
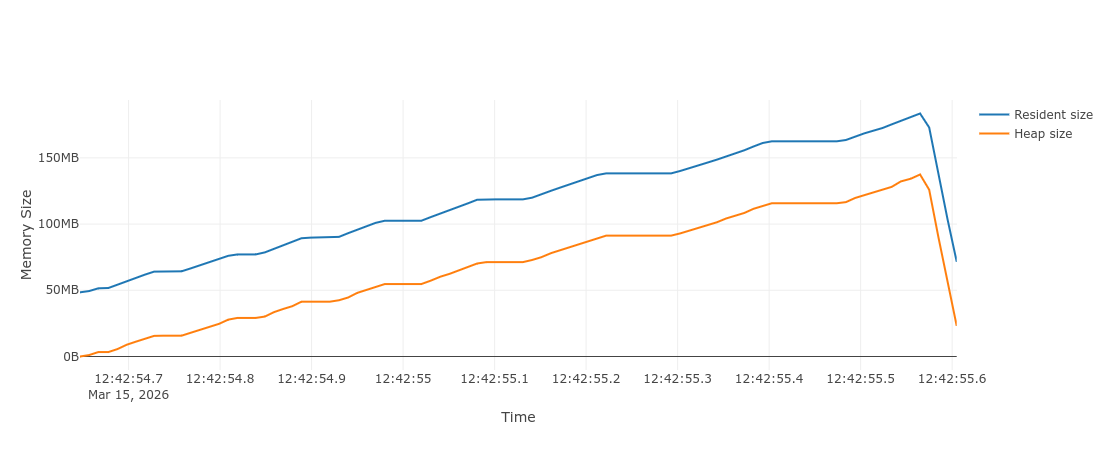
We notice that a good chunk of memory was saved! Now, doing the same with Pydantic models:
from pydantic import BaseModel
class Model(BaseModel):
a: int
b: str
c: int
d: int
e: int
f: int
g: int
model_list: list[Model] = []
for _ in range(1_000_000):
model = Model(
a=1,
b='2',
c=1,
d=1,
e=2,
f=1,
g=1,
)
model_list.append(model)
and...
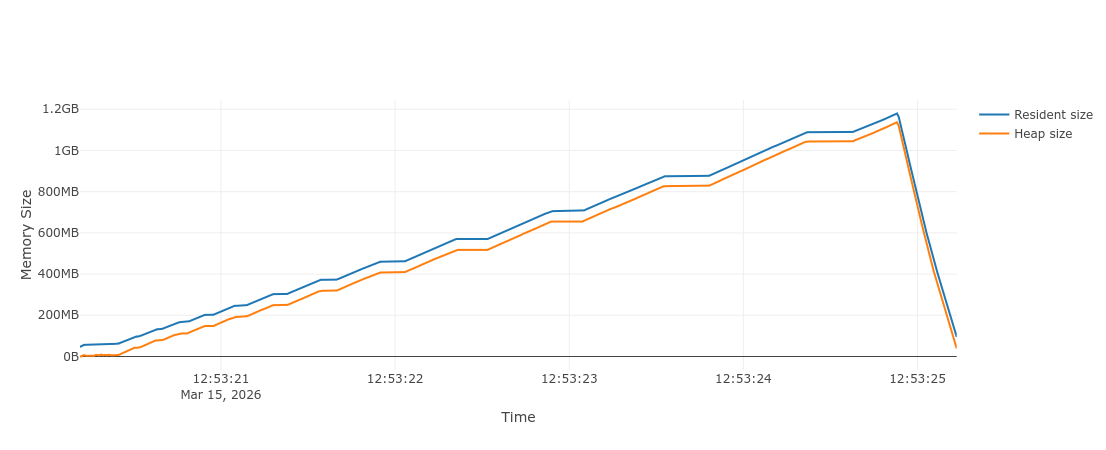
huh, we are using 4x more memory than the example without the PEP 412 optimization?!
Tracking model fields set
Looking at the Memray flamegraph report 1, we can notice one particular call in the model validation logic, accounting for almost 800 MB of the total memory usage:
impl ModelFieldsValidator {
fn validate_by_get_item<'py>(
&self,
py: Python<'py>,
input: &(impl Input<'py> + ?Sized),
dict: impl ValidatedDict<'py>,
state: &mut ValidationState<'_, 'py>,
) -> ValResult<ValidatedModelFields<'py>> {
// Validation of fields...
...
let fields_set = PySet::new(py, &fields_set_vec)?; // <- this line
...
}
}
Apart from validating each field, Pydantic also keeps track of the field explicitly set during instantiation (such fields are accessible using the
model_fields_set property):
from pydantic import BaseModel
class Model(BaseModel):
a: int
b: int = 1
m = Model(a=1)
m.model_fields_set
#> {'a'}
It is currently stored as a (mutable) Python set, we can see by checking its size that it matches the extra 800 MB of memory reported by Memray:
# Using the `Model` class with a, b, ..., g fields above:
model = Model(a=1, b='2', g=1)
(sys.getsizeof(model.model_fields_set) * 1_000_000) / 1_000_000 # (1)!
#> 728.0, roughly matches the 800 MB
- Multiplying by 1M to account for the total number of models, and dividing again to get the result in MBs.
Bitsets to the rescue
Say you are developing an application with a bunch of feature flags. For every user of your application, specific feature flags can be turned off and on. A naive approach would be to store the feature flags configuration as a list of boolean values:
feature_flag_values = [
True, # new_dark_mode
False, # sso_login
False, # admin_panel
True, # ai_features
]
But this turns out to be particularly inefficient, especially for booleans. Each element of the list is a reference to the boolean value True/False
(in Python, references are 8 bytes in size, 64 times more than the theoretical size to store an on/off value).
Let's say we have 8 different feature flags in our application. We can represent these using a single u8 number, by using the binary number representation:
| Feature flag | new_dark_mode |
sso_login |
admin_panel |
... | ai_features |
|---|---|---|---|---|---|
| Binary number | 1 | 0 | 0 | ... | 1 |
By assigning an index to the binary position for each feature flag, we can use bitwise operations to read and toggle specific feature flags 2.
Now I hope you can see where this is going. The model_fields_set attribute is used to track whether a field was explicitly set during validation.
This is an on/off value! And luckily for us, Pydantic model fields are ordered,
meaning we can easily convert from a field name -> index into the binary number representation.
Implementation
There are a couple requirements for Pydantic models to be able to work with bitsets:
-
The number of model fields (and as such number of bits) is arbitrary. A
u8could be enough if a model has 5 fields, but in theory it could also have thousands of fields.Depending on the number of fields, we can use the appropriate number type (
u8for up to 8 fields,u16for up to 16 fields, etc). If the model happens to have more than 128 fields, a vector of numbers can be used. Thefixedbitsetcrate handles this nicely for us. -
Extra fields are also tracked in
model_fields_set:from pydantic import BaseModel class Model(BaseModel, extra='allow'): a: int model = Model(a=1, extra=2) model.model_fields_set #> {'a', 'extra'}If any extra fields are set during validation, we can collect them in a separate set.
Putting it all together, here is a sketch API of our new set implementation 3:
from collections.abc import MutableSet
class ModelFieldsSet(MutableSet[str]):
bitset: FixedBitSet # (1)!
extra_keys: set[str] | None
# A reference to the `model_fields` property of the model:
model_fields: dict[str, FieldInfo]
def _index_of(self, key: str) -> int | None:
for i, k in enumerate(self.model_fields):
if k == key:
return i
def __len__(self) -> int:
bitset_len = self.bitset.count_ones()
if self.extra_keys is not None:
return bitset_len + len(self.extra_keys)
else:
return bitset_len
def __contains__(self, key: object) -> bool:
if not isinstance(key, str):
return False
idx = self._index_of(key)
if idx is not None and self.bitset.contains(idx):
return True
if self.extra_keys is not None and key in self.extra_keys:
return True
return False
# Other methods:
def add(self, key: str) -> None: ...
def discard(self, key: str) -> None: ...
- This would be the
FixedBitSetstruct in Rust.
The (very much in progress) implementation can be found in this PR.
Results
In terms of memory, we end up saving almost all the 800 MB used by the original set:
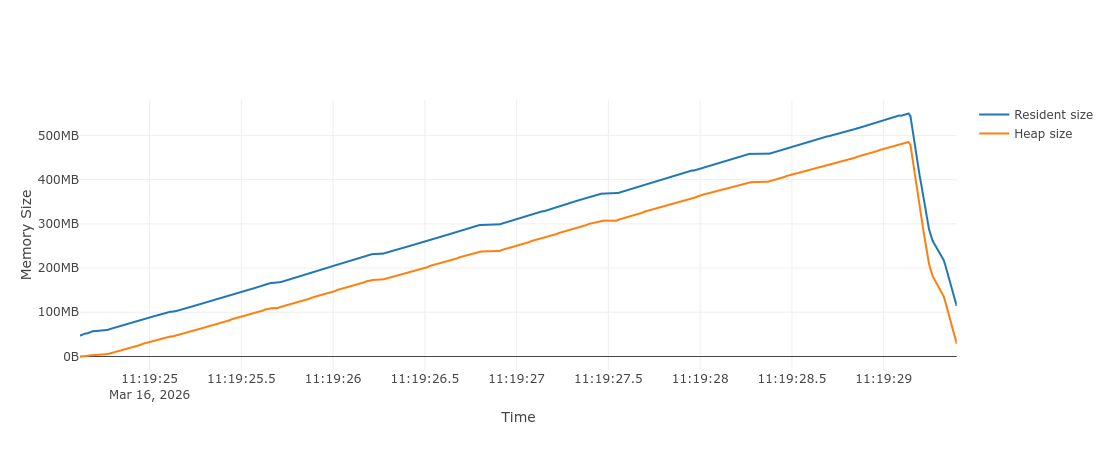
A 55% reduction! Note that most of the time, the relative improvement will be lower than that, as we used really small field values in our model
(e.g. we are not using more complex types such as containers or datetimes).
In terms of validation speed, it greatly improved on some of our benchmarks, especially the ones defining models with lots of fields. Interestingly, when only one or two fields are defined on the model, validation is slightly slower, presumably because creating a Python set was faster than the new bitset implementation. This can be mitigated by only using the new implementation if the number of fields is big enough.
Open source challenges
Whenever we need to make changes to the Pydantic library, we need to be extremely careful about potential breaking changes. The library has widespread usage, and as such we should always expect it to be used in unusual and undocumented ways.
As of today, model_fields_set is exposed
as a property, and typed as set[str]. As such, we should assume that users expect the value to be a built-in set.
This means isinstance(m.model_fields_set, set) should work (and in theory type(m.model_fields_set) is set too..), it should be (un)picklable,
We should also probably expect users to override it completely with a different set instance (and still be supported during serialization if
exclude_unset is enabled).
Yes, model_fields_set is a property and as such can't be overridden, but the actual value is stored under the __pydantic_fields_set__ attribute,
which is relied on already.
These are all challenges that will complicate the implementation, and may require waiting for V3.
As general advice to open source maintenance, be as conservative as possible when exposing your public API. If something isn't documented but possible to do, users will rely on it.
Use Pydantic Validation? Try Pydantic AI and Pydantic Logfire. Same type-safety you trust, now for AI agents, evals, and observability.
References
Footnotes
-
The
memray runcommand has a--nativeargument, useful for finding which regions of the code are responsible for holding the memory. As the Pydantic validation is performed in Rust, this can help us find where in the Rust validation memory is being used. ↩ -
See this video from the Core Dumped Youtube channel for an in depth explanation. It provides a really similar example to our feature flags. ↩
-
The actual implementation lives in
pydantic-coreand is written in Rust, but a Python example is provided for clarity. ↩
