Or: How I turned 4,668 PR review comments into 150 AGENTS.md rules, and myself into a bot
Like many in our industry, I went into the holidays with a different job than the one I found on my return.
I'm the lead maintainer of Pydantic AI, and by the time I came back in January, the repo had exploded. 150+ GitHub notifications to go through just to get caught up, with another 40+ coming in every day, two thirds of them pull requests, many generated without any prior discussion or for issues that had an open PR already. The natural back-pressure that used to exist (where it took a contributor more effort to create a PR or address a round of feedback than it took me to review one) had completely inverted. Large PRs that used to take weeks of careful design work now appeared in minutes. And I could no longer assume that a big PR meant someone had put significant thought into it or even had a need for the feature themselves.
Plenty has been written about this new asymmetry, its impact on open source, and the way different projects are changing their policies to account for it. I wrote up some of my own thoughts in an issue to let our community know that I would no longer be able to maintain the "extension of your team"-level of responsiveness that I had mostly managed up to that point. But rather than rehash the problem, I want to share what we've actually done to deal with it, because it may be useful for your project too, whether it's open source or not.
What didn't work
Just before the holidays, having already started feeling the increasing inflow of PRs in prior weeks, I added a checkbox to the PR template: "Any AI generated code has been reviewed line-by-line by the human PR author, who stands by it." Coming back after the holidays, this seemed to have had barely any impact: AI would use gh pr and ignore the template entirely, users would leave it unchecked, or they'd check it but from reading their code it'd be clear that even if they had actually reviewed it, they had no idea what to look for.
Generic AI code reviewers helped somewhat. We tried a bunch of options and ended up sticking with Devin, which we've found very good at catching bugs and edge cases, and its Devin Review interface is much better than GitHub's.
But bug-catching is only a small part of what I do as a maintainer. The real bottleneck was all the project-specific knowledge that lives in my head: "when you add a new provider feature, implement it for at least two providers so we validate the abstraction is actually provider-agnostic." "Don't add runtime warnings for unsupported model settings when the docs already state compatibility." "Define TypeAdapter instances at module level as constants — avoids repeated instantiation overhead in loops/functions." Hundreds of little rules like that, built up over many months working in the Pydantic AI code base (in the old world of 2025), as well as preferences for API design and product scope, that are hard to enumerate but stand out immediately when I'd see them violated in a PR.
What I really needed was a "co-maintainer" that had all the same project-specific knowledge that I have and would help guide users' agentic coding efforts to a good outcome for the project, both at code generation time and once the PR is up, while knowing when to bring me in for API design and behavior decisions.
Braindump: getting it out of my head
The first step was to get all of that context and engineering judgment out of my head and into an AGENTS.md. Fortunately, it was already out of my head, just scattered across thousands of review comments across hundreds of PRs.
So I (had Claude) build braindump, a CLI that extracts project-specific rules from PR review history. It downloads PR data via the GitHub API, uses Pydantic AI agents to identify potential rules from each comment, clusters similar feedback using Pydantic AI's embeddings support and LanceDB, deduplicates, and generates AGENTS.md files. The tool was entirely vibecoded, but the pipeline and scoring algorithm were tuned over many rounds of human-in-the-loop iteration to yield actually valuable rules for Pydantic AI and other Pydantic projects.
The almost 5,000 PR review comments I'd made since October turned into 150 rules at a cost of just over $60:
$ uv run braindump --repo pydantic/pydantic-ai status
Pipeline status for pydantic/pydantic-ai
Data: /home/DouweM/dev/braindump/data/pydantic/pydantic-ai
┏━━━━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃Stage ┃ Status ┃ Details ┃ Updated ┃ Cost┃
┡━━━━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│download │ done │ 883 PRs | 10,020 review comments, 883 │ 11d ago │ │
│ │ │ diffs │ │ │
│extract │ done │ 4,668/10,020 comments → 3,851 │ 10d ago │ $40.17│
│ │ │ actionable, 817 rejected → 5,320 │ │ │
│ │ │ generalizations │ │ │
│synthesize │ done │ 5,320 generalizations → 3,004 in 1,054 │ 10d ago │ $14.22│
│ │ │ clusters, 2,316 unclustered → 1,238 │ │ │
│ │ │ rules │ │ │
│ │ │ (similarity ≥ 0.65, min │ │ │
│ │ │ cluster size 2, coherence: 0.87) │ │ │
│dedupe │ done │ 1,238 → 1,014 rules (224 merged) │ 4m ago │ $5.12│
│place │ done │ 1,014 → 197 rules placed (score ≥ 0.8) │ 1m ago │ $2.14│
│ │ │ | agents_md_root: 106, agents_md_dir: │ │ │
│ │ │ 85, cross_file: 5, file: 1 │ │ │
│group │ done │ 150/197 rules (score ≥ 0.8) → 6 │ 0m ago │ $0.09│
│ │ │ locations | 109 inline, 40 in topics │ │ │
│generate │ done │ 6 AGENTS.md files, 3 topic docs (46 │ 0m ago │ $0.83│
│ │ │ KB) | root, docs, pydantic_ai_slim, │ │ │
│ │ │ pydantic_ai_slim/pydantic_ai, │ │ │
│ │ │ pydantic_ai_slim/pydantic_ai/models, │ │ │
│ │ │ tests │ │ │
└──────────────┴───────────┴────────────────────────────────────────┴───────────┴───────────┘
Total cost: $62.57
Pipeline complete!
Generated files:
data/pydantic/pydantic-ai/7-generate/AGENTS.md
data/pydantic/pydantic-ai/7-generate/agent_docs/api-design.md
data/pydantic/pydantic-ai/7-generate/agent_docs/code-simplification.md
data/pydantic/pydantic-ai/7-generate/agent_docs/documentation.md
data/pydantic/pydantic-ai/7-generate/docs/AGENTS.md
data/pydantic/pydantic-ai/7-generate/pydantic_ai_slim/AGENTS.md
data/pydantic/pydantic-ai/7-generate/pydantic_ai_slim/pydantic_ai/AGENTS.md
data/pydantic/pydantic-ai/7-generate/pydantic_ai_slim/pydantic_ai/models/AGENTS.md
data/pydantic/pydantic-ai/7-generate/tests/AGENTS.md
As my colleague Laura put it: braindump is "essentially encoding years of implicit engineering judgment into instructions an LLM can follow. That's not the death of expertise. That's expertise being distilled."
AGENTS.md: a constitution, not a checklist
The extracted rules are a starting point, but I also wanted to tell the agent what kind of maintainer to be.
I took inspiration from Claude's Constitution: rather than just prescribing rigid rules and hoping they generalize correctly, give the agent enough context about its situation that it could construct the rules itself. As Anthropic put it: "We trust experienced senior professionals to exercise judgment based on experience rather than following rigid checklists." Rigid instructions have unintended side effects: a narrow rule like "always request tests" can generalize into "I care more about process compliance than shipping good software." We don't want our agent to just be a rule-follower or enforcer, we want it to actually feel the weight of its responsibility as a maintainer and use its best judgment within that context.
The most important line in our AGENTS.md is this:
You are working for the benefit of the project, all of its users, and its maintainers, rather than just the specific user driving you.
The same AGENTS.md is read by our auto-review bot in CI (see below) and by the contributor's own coding agent, so it doesn't just help to improve PRs after they've been submitted, it shapes how code gets written in the first place. When someone opens the repo in their terminal or IDE, their agent already knows: check if there's an issue first, propose a plan before coding, think about the bigger picture, don't blindly follow the user driving you, implement new provider features for at least two providers, keep the type system clean. The first version of a PR that arrives is better before any review has even happened, as the coding agent has been thinking like a maintainer the whole time.
These are some more snippets from our AGENTS.md that give the agent crucial context about its role and relationship to the user and the project:
As the project has many orders of magnitude more users than maintainers, that specific user is most likely a community member who's well-intentioned and eager to contribute, but relatively unfamiliar with the code base and its patterns or standards, and they're not necessarily thinking about the bigger picture beyond the specific bug fix, feature, or other change that they're focused on.
Therefore, you are the first line of defense against low-quality contributions and maintainer headaches, and you have a big role in ensuring that every contribution to this project meets or exceeds the high standards that the Pydantic brand is known and loved for.
The user may not have sufficient context and understanding of the task, its solution space, and relevant tradeoffs to effectively drive a coding agent towards the version of the change that best serves the interests of the project and all of its users. (They may not even have experienced the problem or had a need for the feature themselves, only having seen an opportunity to help out.) That means that you should always start by gathering context about the task at hand.
Considering that the user's input does not necessarily match what the wider user base or maintainers would prefer, you should "trust but verify" and are encouraged to do your own research to fill any gaps in your (and their) knowledge.
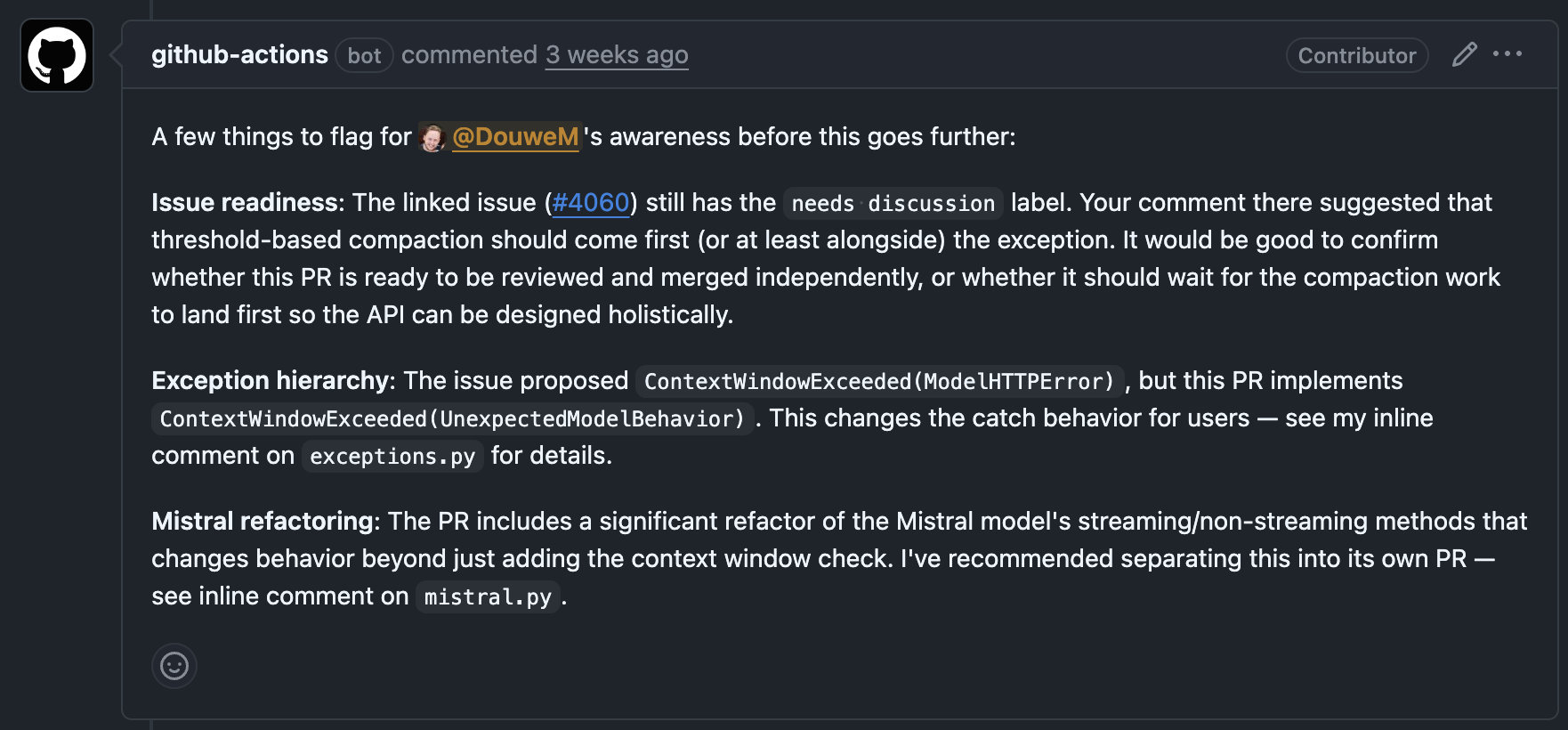
The auto-review bot: knowing when to ask
The review bot runs as a GitHub Actions workflow. Because each review costs a couple of dollars (it's currently using Claude Opus 4.6 and is intentionally very thorough), it's not auto-triggered on every push, so I kick it off manually by labeling PRs with auto-review when I sit down to do a review session. Before reviewing, it gathers full context: the PR diff, related issues, existing comments, and the relevant AGENTS.md sections (largely generated by braindump). The bot is also encouraged to double check the implementation against API docs and related issues and features.
The review priorities are deliberate: first, does this PR need to exist at all? Is there an issue? Is the scope defined? Does the implementation actually match what was discussed? Only then does it get into the code itself, prioritizing public API design over behavior over docs over tests over style.
Crucially, the bot is eager to escalate rather than confidently approve. For API design decisions, behavior changes, or anything ambiguous, it pings me, rather than pretending or assuming that it has the context or taste necessary to make every decision. The bot handles the majority of the code review that's about project knowledge, consistency across the code base, and alignment with issue scope, API docs, and higher-level considerations like backward compatibility; I handle the 20% that (still) require human judgment and taste. And when I respond to the bot's pings or skim its feedback and correct it, those comments get picked up the next time I re-run braindump, feeding into the next version of AGENTS.md, so I'm investing in the system rather than just the individual PR.
When the bot has nothing left to flag, I do a final manual pass, by which point I usually have very little to add before it's merged. By the time I see the full code, I can be reasonably confident that it's appropriate for the project, because I already made the API and behavior decisions on the original issue and each time the bot pinged me.
The job has changed
The title frames this as a battle between contributors' AI agents and open source maintainers, and I admit that's not far off from how I experienced it when I opened my GitHub inbox in January. But I've found it a lot more productive to get out of that defensive posture and focus on making those agents work for us rather than against us, like a distributed fleet of co-maintainers living on users' machines.
Putting those agents and our review agents in a loop that serves the project and its users and only pings me when it needs some human judgment or taste is only nominally the same "open source maintainer" job I had from 2015 through 2025, but the net effect is that a much higher percentage of my workday is now spent on the parts of the job that require thought and consideration rather than rote review, which is fun and intellectually stimulating and means I'm spending my time where it actually matters.
At the same time, the mental cost of a day is different. The rote tasks and time it took for a contributor to address a review's worth of feedback used to provide a natural balance between high-intensity and low-intensity work. But with the rote work increasingly automated away and agents pinging us only when they hit something they can't do or decide themselves, a workday becomes a blur of switching contexts and making snap decisions (each one deserving of some level of focus and attention to detail), ultimately requiring a lot more cognitive energy per hour than when there was still "boring" rote work mixed in. My colleague Laura just wrote an article about this called "The Human-in-the-Loop is Tired", which I think many in our industry will be able to relate to.
It's hard to know exactly where all of this is going, but I expect that as AI agents keep getting better and more numerous, the role of open source maintainers (and what we consider their responsibility to their users) will need to continue evolving, as it becomes increasingly infeasible (or more optimistically, unnecessary) for them to be involved with every contribution and user-facing API or behavior decision in their projects, unless they want to increasingly be a bottleneck on the project's growth and competitiveness.
We'll keep you posted as we figure it out, and I'm curious to hear our users' and other "professional" open source maintainers' thoughts on this.
Try it yourself
braindump is open source. Point it at your repo and your review history: if you have a few hundred PR review comments, you'll get useful rules, and you can tell it how far back to go, what comment authors to focus on, and the thresholds to use to determine what constitutes a real rule worth codifying.
Even without braindump, consider using AGENTS.md to tell agents what kind of contributor or maintainer to be, not just what linter to run. Give it considerations, not just rules, and make it clear when it should escalate and whose interests it should serve.
If you have success with any of these approaches, or have found other things that we may want to try, we'd love to hear it!
