Live Evals
Use Evals: Live Monitoring to watch the results of online evaluations running against real traffic. An online evaluation scores an agent or function after it runs, so it helps you notice a production regression, investigate an unexpected result, or follow a new evaluator rollout.
This page is for monitoring results that already reach Logfire. To add an evaluator to your application, follow the Pydantic AI online evaluation guide. For a curated test set before deployment, use offline evaluations instead.
Live Evaluations reads gen_ai.evaluation.result OpenTelemetry log events that include a target and evaluation name. The @evaluate decorator for functions and the OnlineEvaluation capability for Pydantic AI agents emit these events by default.
Open Evals: Live Monitoring from the sidebar. The target list shows agents and functions with recent online-evaluation activity. A target is the agent or function that produced an evaluation result.
- Choose a time range at the top of the page. Start with 24h for a normal operating view, then narrow it when investigating a recent deployment or broaden it to compare a longer period.
- Find the target you want to inspect. Each row shows the target type, its evaluators, the number of events, and when the last event arrived.
- Read the evaluator summaries. They show a pass rate for pass/fail checks, an average for numeric scores, or one label plus the number of other labels seen. The small activity bars show when results arrived in the selected time range.
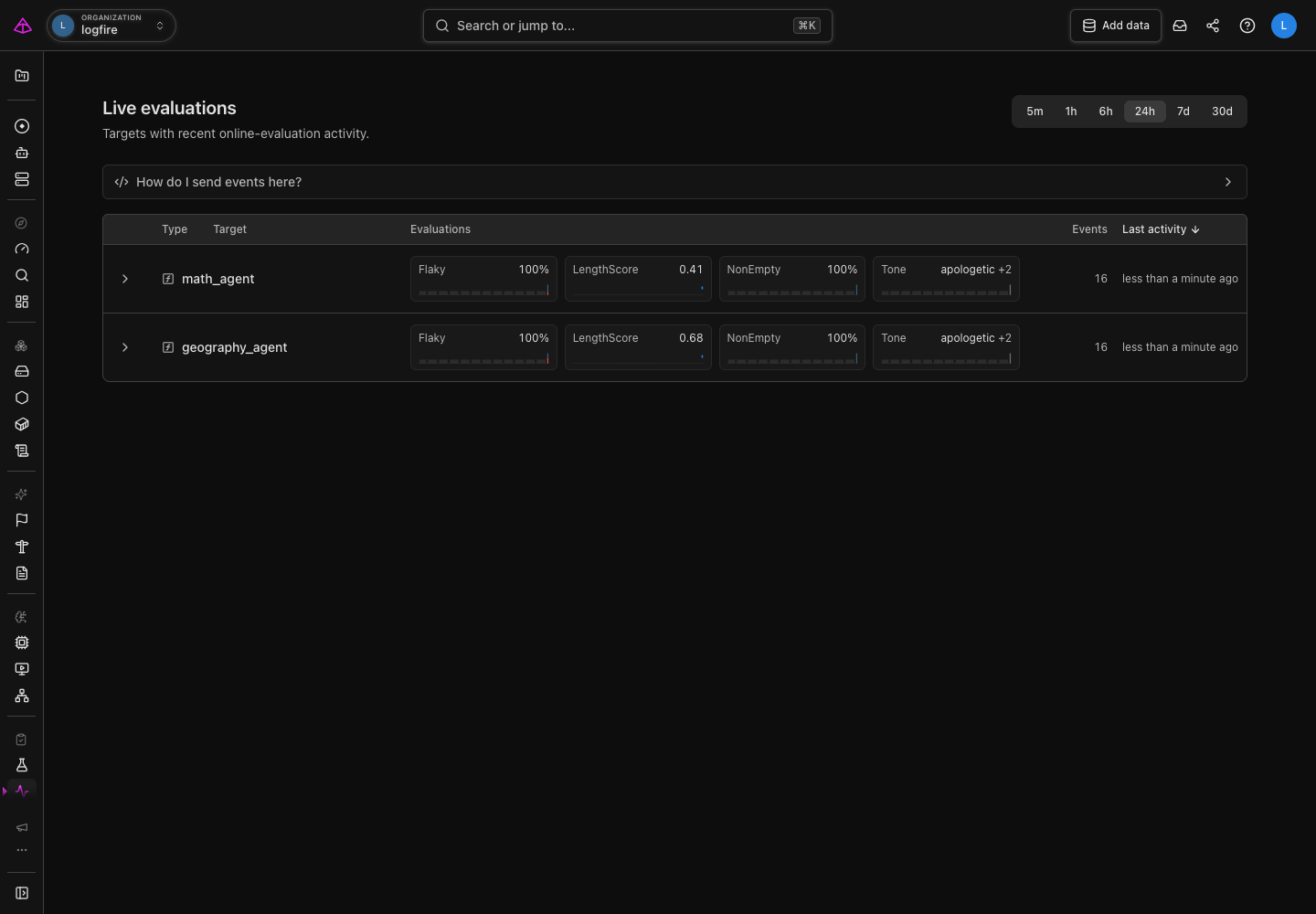
The target list is a fast health check, not the whole story. Use the chevron beside a target to expand its evaluator breakdown without leaving the page. Open the target when a summary changes or looks unfamiliar.
A target seen within the last 30 days remains in the list even when it has no events in the selected time range. It appears with zero events and no current score, so narrowing the range does not hide configured evaluators that are currently quiet.
Select a target to open its detail page. It brings together the evaluation results for that target in the selected time range.
- Start with the evaluator cards. They show the current summary, recent activity, and any errors raised while running that evaluator.
- Review Recent events for the individual results and their explanations. Use the evaluator filter to focus on one check.
- Select the trace link on an event to open it in Live View. A trace is the record of the request that produced the evaluated result. It lets you inspect the evaluation event and any prompt, response, tool-call, or other context that your application recorded.
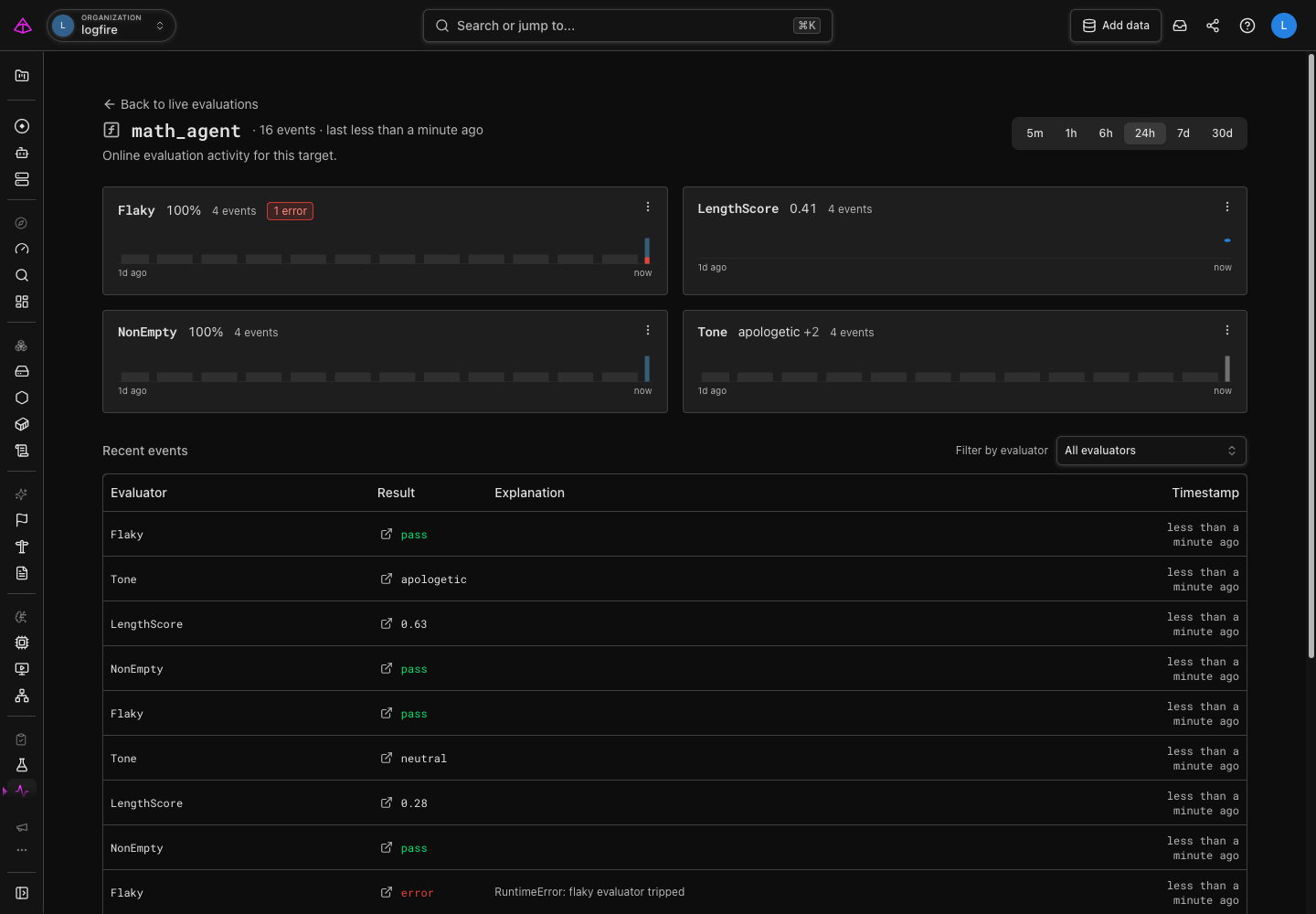
An evaluator error is different from a failed evaluation: it means the evaluator itself could not produce a result. Open its trace and explanation first, then decide whether the application behavior or the evaluator needs attention.
The page presents a result according to the value returned by the evaluator:
| Evaluator output | Target-list and detail-page summary |
|---|---|
bool | Pass rate, with individual pass or fail results |
| Number | Average score over the selected time range |
| String | One label, plus the number of other labels seen |
An evaluator that returns multiple named scores appears as one result for each score. If you deploy a new evaluator version, use the detail page to compare the version badges and recent events while both versions are running.
Live Evaluations groups results by target and evaluation name, regardless of the evaluator source or configuration. Give results distinct names when they should appear as separate summaries.
Use a hide rule when an old experiment, test evaluator, or retired version makes the monitoring view harder to read. Open an evaluator’s overflow menu on the target detail page and choose the matching hide action. You can hide that evaluator for the target or data that arrived before the current time while allowing new events to remain visible. When the selected range contains one recorded evaluator version, the menu also offers an action for that version.
Hide rules affect Evals: Live Monitoring only. They do not delete telemetry, change traces, or remove evaluation events from alerts and SQL queries.
Rules created from an evaluator’s overflow menu are scoped to that target. On the Hidden Evaluators project settings page, you can add, edit, and remove rules, or leave the target empty to match evaluators across the project. Every populated field in one rule must match an event; an event is hidden when any active rule matches it. Removing a rule makes its matching entries visible again.
After adding online evaluations to an application and sending traffic through it, you should see:
- a target row for the evaluated agent or function;
- one summary for each evaluator or named score; and
- a recent event that opens the parent trace in Live View.
If all three appear, Logfire is receiving evaluation results and preserving their link to the request that produced them.
No evaluation activity yet: Confirm the application is configured to send telemetry to the intended Logfire project, then exercise the evaluated code path. Try a wider time range before assuming no events arrived.
An evaluator shows an error: Open its recent event and follow the trace link. The event explanation and trace identify whether the evaluator raised or the application result failed the check.
A result appears under an unfamiliar target: Check the target name passed by your evaluation integration. The page groups results by that agent or function name.
A function inside an agent has type function: This is expected for the @evaluate decorator, which keeps the decorated function as its target even when the function runs inside a Pydantic AI agent. The OnlineEvaluation capability emits results for the agent target.